
Stambia Data Integration
Dans un contexte ou la data est au cœur des organisations, l'intégration des données devient un processus clé de réussite des transformations digitales. Pas de transformation numérique sans mouvement ou transformation des données.
Les organisations doivent relever plusieurs challenges :
- Pouvoir désiloter les systèmes d'information
- Traiter de manière agile et rapide des volumes de données croissants et des types d'information très différents (donnée structurée, semi-structurée ou non structurée)
- Gérer tout aussi bien des chargements massifs que des ingestions au fil de l'eau des données, afin de prendre des décision pertinentes
- Maîtriser les coûts d'infrastructure de la donnée
Dans ce contexte Stambia répond en apportant une solution unifiée pour tout type de traitement de la donnée, qui peut être déployée aussi bien dans le cloud que sur site, et qui garantie une maîtrise et une optimisation des coûts de possession et de transformation de la donnée.
Pour en approfondir ces points, consulter notre page Pourquoi Stambia ?
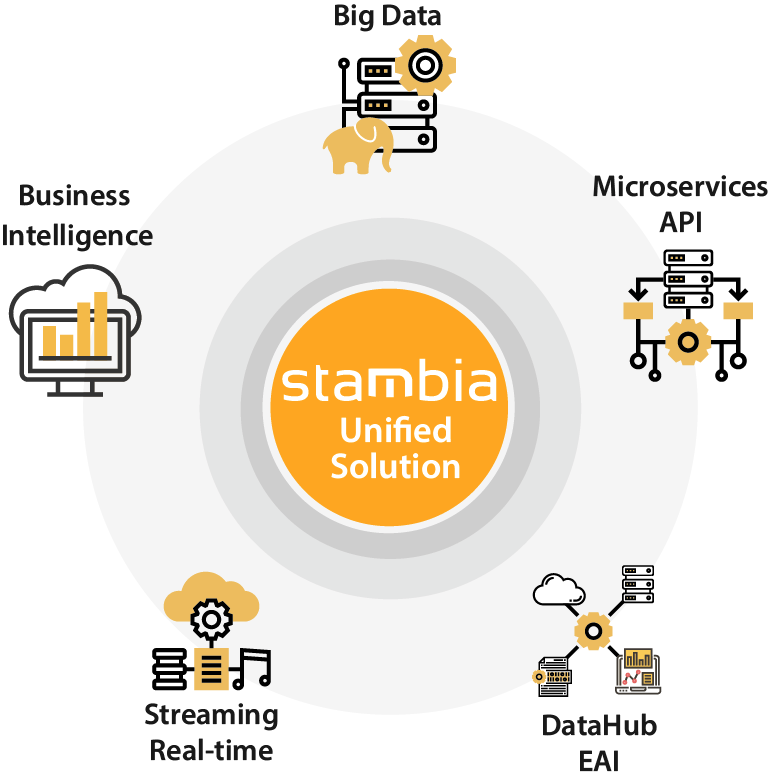
Les cas d'usage de Stambia Data Integration
Les projets avec Stambia
Avec une architecture unique et la même plateforme de développement, Stambia Enterprise permet d'aborder tout type de projet d'intégration de données, que ce soit les projets adressant de très larges volumétries de données ou les projets plus orientés temps-réel.
Voici une liste non exhaustive de projets réalisables :
- Alimentation de bases de données décisionnelles (datawarehouses, datamarts, infocentres), business intelligence
- Projet Big Data, Hadoop, Spark et No SQL
- Migration de plateforme vers le Cloud (Google Cloud Plateform, Amazon, Azure, Snowflake…)
- Echanges de données avec des tiers (API, Services Web)
- Projet de Data Hub, échanges de données entre applications (mode batch ou temps-réel, exposition ou utilisation de Services Web)
- Réplication de données entre bases hétérogènes
- Intégration ou production de fichiers
- Gestion de référentiels de données métiers
Quelques exemples d'architectures avec Stambia
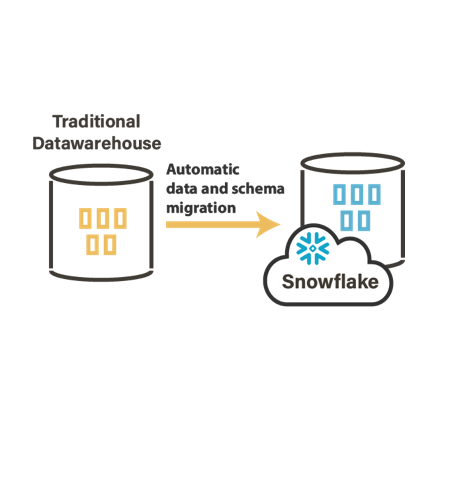
Comment fonctionne Stambia Data Integration ?
Stambia repose sur plusieurs concepts clés
Un Mapping Universel
Contrairement aux approches traditionnelles, orientées process techniques, Stambia propose une vision dite "universelle" du mapping : toute technologie doit pouvoir être alimentée ou lue de manière simple, quelle que soit sa structure et sa complexité (table, fichier, Xml, Service Web, Application SAP, ...). C'est une vision Data, orientée métier.
Pour en savoir plus consulter la page "Mapping Universel".

Une approche par les modèles
L'approche Stambia est basée sur les modèles. La notion de templates ou de technologies adaptatives offre une capacité d'abstraction et d'industrialisation des flux. Cette démarche permet de gagner en productivité, en agilité et en qualité sur les projets réalisés.
Pour en savoir plus consulter la page "L'approche par les modèles".

Un mode ELT
L'architecture en mode "délégation de transformation ou ELT permet de maximiser les performances, diminuer les coûts d'infrastructure, et maîtriser les flux réalisés.
Pour en savoir plus consulter la page "L'approche ELT".

Une maîtrise de la trajectoire
La vision de Stambia est de permettre à ses clients de maîtriser les coût de possession des plateformes d'intégration de données. Ceci est possible grâce au modèle économique de Stambia et aux approches technologiques choisies qui permettent d'augmenté la productivité et de dominuer la courbe d'apprentissage.
Pour en savoir plus consulter notre Offre tarifaire.
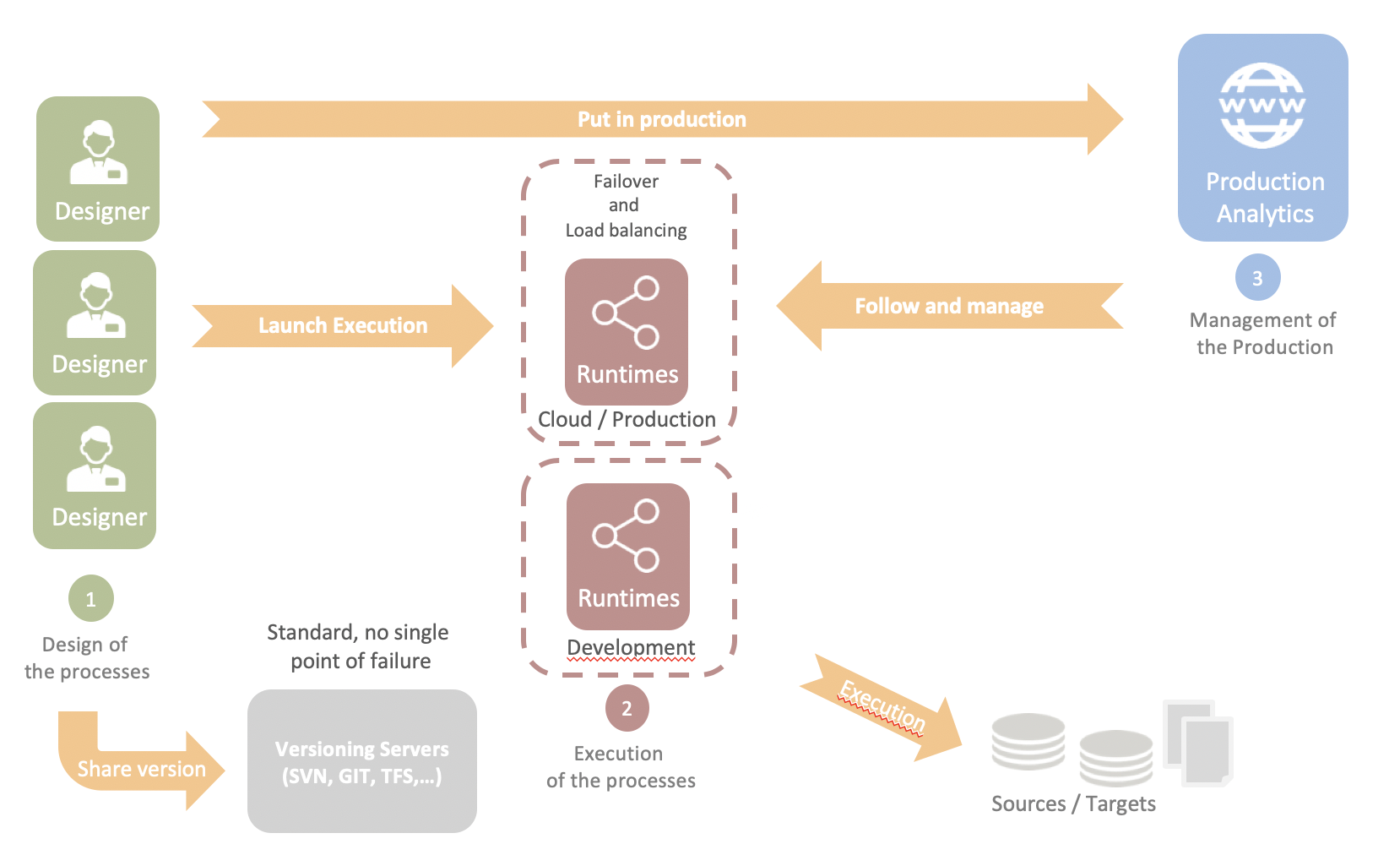
Et une architecture simple et légère
L'architecture de Stambia Enterprise repose sur trois composants simples :
- Les Designers sont les postes de développement et de test. Les Designers reposent sur une architecture Eclipse facilitant le partage ainsi qu'une gestion souple des développements et des projets en équipe.
- Les Runtimes sont les processus qui exécutent les jobs en production. Ils reposent sur une architecture Java facilitant leur déploiement sur site ou dans le Cloud. Ils sont compatibles avec Docker et les architectures Kubernetes
- Stambia Analytics est le composant web permettant la mise en production (déploiement, paramétrage et planification) et le suivi des jobs, ainsi que le pilotage des différents runtimes.
Spécifications et pré-requis techniques
| Spécifications | Description |
|---|---|
|
Architecture simple et agile |
|
| Connectivité |
Vous pouvez extraire les données de :
Pour plus d'informations, consulter notre documentation technique
|
| Connectivité technique |
|
|
Caractéristiques standard |
|
| Caractéristiques avancées |
|
| Pré-requis techniques |
|
| Déploiement Cloud | Image Docker disponible pour les moteurs d'exécution (Runtime) et la console d'exploitation (Production Analytics) |
| Standard supportés |
|
| Langage de Scripting | Jython, Groovy, Rhino (Javascript), ... |
| Gestionnaire de sources | Tout plugin supporté Eclipse : SVN, CVS, Git, ... |
| Migrer depuis votre solution existante d'intégration de données | Oracle Data Integrator (ODI) *, Informatica *, Datastage *, talend, Microsoft SSIS * possibilité de migrer simplement et rapidement |
Vous souhaitez en savoir plus ?
Consultez nos différentes ressources





Vous n’avez pas trouvé ce que vous souhaitez sur cette page ?
Consultez nos autres ressources :
- [Techno] Le Mapping Universel Stambia
- [Techno] L'approche ELT
- [Techno] L'approche par les modèles
- [Techno] Le concept de plateforme adaptive
- [Solution] Comprendre l'architecture Data Hub
- [Produit] Composant Salesforce
- [Produit] Publier et consommer des API et Microservices
- [Produit] Gérer vos projets Big Data Hadoop

eBook : Stambia expliqué en 5 minutes
Livre Blanc : Le futur de l'intégration de données agile avec Stambia
Stambia annonce son rapprochement avec Semarchy.
La solution Stambia devient Semarchy xDI Data Integration