
Composant Stambia pour Apache Spark
Apache Spark est un framework open source pour le Big Data, bien connu pour sa vitesse élevée de traitement des données et sa facilité d'utilisation. Il offre une réutilisabilité, une tolérance aux pannes, un traitement en temps réel et bien d'autres fonctionnalités.
Le composant Stambia pour Apache Spark est conçu pour offrir aux utilisateurs la possibilité d'automatiser, d'industrialiser et de gérer vos projets Spark, avec plus d'agilité dans vos implémentations et développements.

Apache Spark: Pourquoi choisir une solution E-LT ?
Automatisez vos efforts en code et gestion de vos applications Spark
Lorsque vous travaillez sur des projets qui traitent du Big Data, Apache Spark est le plus souvent utilisé pour un traitement de données volumineux. Spark est utilisé par les ingénieurs de données ( data scientist ou data analyst ) pour effectuer diverses opérations et analyses de données. Beaucoup de développement est nécessaire lors de la création d'applications Spark. Souvent complexes les développements deviennent difficiles à maintenir dans le temps. Automatiser cet effort peut être très bénéfique pour la productivité de vos développeurs.
Par exemple, si une application Spark a été développée dans un langage Java elle deviendra difficile à interpréter et mise à jour par un autre membre de l'équipe ayant des compétences en Python. Une solution est de mettre en place une couche d'abstraction cohérente, de sorte que la conception soit agnostique du code produit en arrière-plan, et ainsi d'offrir davantage d'agilité.
De nombreuses organisations migrent leurs données vers le cloud, certaines sont de type hybrides et maintenant une adoption multi-cloud a commencé. Dans de tels cas, l'utilisation d'outils qui réduisent la complexité du déplacement de votre application Spark vers un environnement différent par une automatisation supplémentaire fait gagner un temps énorme.

Une solution clé en main pour travailler avec le moteur d'analyse unifiée
Apache Spark est connu comme un moteur d'analyse unifié qui possède des modules prédéfinis pour le streaming de données, SQL, Machine Learning etc. Toutes ces fonctionnalités doivent être prises en charge par les outils d'intégration de données.
Cela nécessite une solution qui a la capacité de travailler avec toutes sortes de technologies, tout en fournissant une plate-forme cohérente et unifiée. Dit autrement : être en mesure de gérer des projets traditionnels et Big Data avec la même compétence.
À titre d'exemple, très souvent, des projets comme de simples échanges de données entre applications, le traitement de grosses log (journaux), le traitement de flux en temps réel, etc. sont conçus à l'aide de différents outils d'intégration de données, ce qui ajoute de la complexité au système d'information.
Il est important d'utiliser une solution qui peut fonctionner de la même manière pour la gestion des systèmes de fichiers, de bases de données, des serveurs, des message brokers, des clusters, etc.
Bénéficiez d'un traitement des données plus rapide et de performances améliorées
Apache Spark est connu pour être 100 fois plus rapide que Hadoop, en raison de son optimiseur de requêtes, de son moteur physique, de la réduction du nombre de lectures et d'écritures sur disque et du traitement en mémoire.
Le concept de Resillient Distributed Dataset (RDD) permet de stocker des données en mémoire et de les conserver sur disque uniquement si nécessaire. Spark fournit une API de haut niveau en Java, Scala, Python et R et a intégré des modules d'apprentissage automatique (machine learnin, deep learning...).
Lorsque vous utilisez une solution d'intégration de données, il est donc nécessaire que Spark fasse le gros du travail. Les outils ETL à moteur propriétaire sont souvent trop lourds pour être utilisés avec Spark.
D'une part, le moteur ETL ne sert à rien quand vous avez déjà Spark, d'autre part le temps passé dans l'administration, la configuration devient fastidieux.
Une solution qui complète Spark en offrant plus d'automatisation, de flexibilité et d'adaptabilité contribue à l'agilité dans vos projets

Capacité à s'adapter aux améliorations constantes d'Apache Spark
Apache Spark étant open source est continuellement mis à niveau par la communauté pour ajouter de nouvelles fonctionnalités et améliorations.
Les développeurs doivent suivre les dernières évolutions Spark pour continuer à mettre à jour leurs applications, cela afin de profiter des nouvelles fonctionnalités.
Dans certains cas, cela peut avoir un impact sur les processus existants et nécessute des efforts importants pour la mise à niveau.
Dans une telle situatuion, une solution qui peut aider à réduire ce temps et les efforts requis pour la mise à niveau, va vraiment simplifier les choses. Les développeurs pourront alors se concentrer sur leur travail du quotidien.
Réduisez votre coût de possession
Étant un framework open source, Spark est également rentable en termes de type de stockage nécessaire par rapport à Hadoop.
En raison de sa facilité d'utilisation et de la disponibilité de diverses API dans différentes langues, les développeurs possédant ces compétences peuvent facilement commencer à créer des applications.
Lorsque vous utilisez une solution d'intégration de données pour votre projet Spark, il est primordial de prendre en compte le coût d'achat et la propriété à long terme de la solution.
Caractéristiques du composant Stambia pour Apache Spark
Le composant Stambia pour Apache Spark fournit un moyen facile par simple glisser-déposer pour concevoir vos intégrations de données avec Spark.
Voici certains des principaux avantages de l'utilisation du composant:
- Automatisation - À l'aide du mappeur de données universel, les programmes Spark sont générées automatiquement puis exécutés.
- Industrialisation - Différents types de modèles Spark, écrits une seule fois, peuvent être distribués à différentes équipes
- Facile à gérer - Apportez des modifications à l'aide d'une interface graphique au lieu de travailler sur un code écrit et complexe
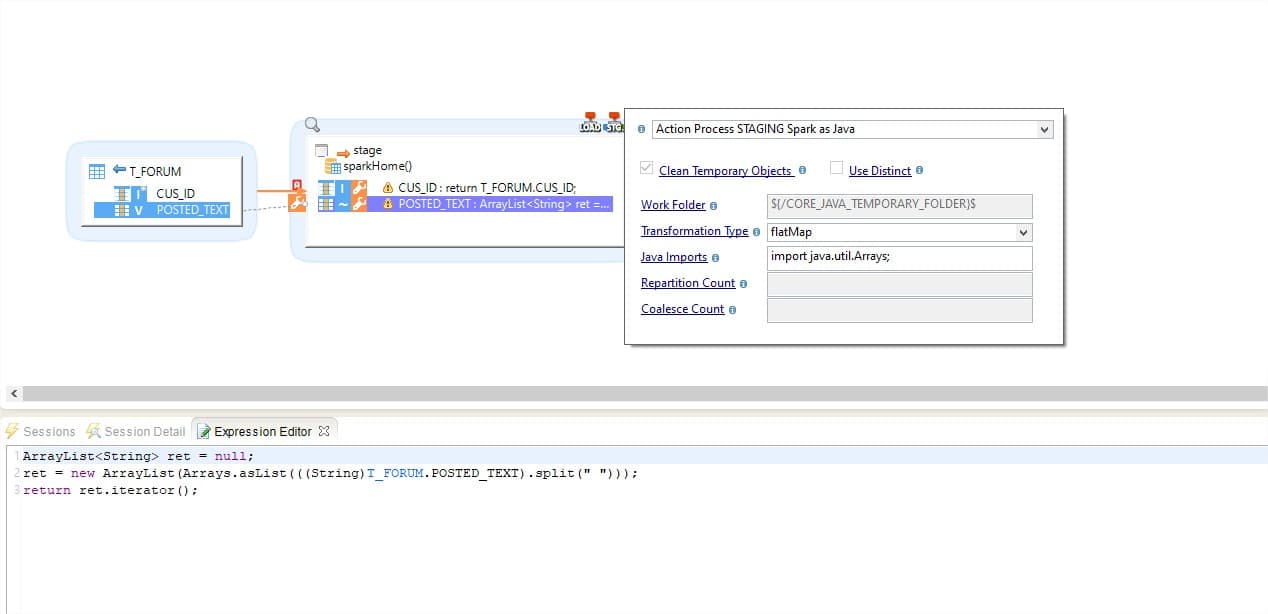
Automatisez avec Stambia pour générer des applications Spark en Drag n Drop
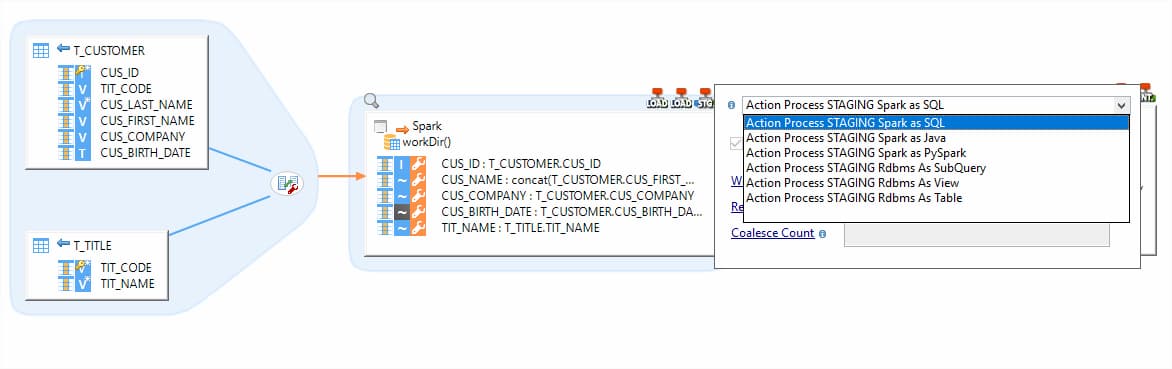
Stambia fournit un Mappeur de Données universel (UDM), basé sur une approche descendante (top down). À l'aide de l'interface graphique, vous gérez votre extraction de données de la source vers le cluster Spark et écrivez les transformations Spark.
Grâce à l'UDM, vous fournissez des instructions par des configurations rapides, qui lors de l'exécution sont utilisées par les modèles ( templates ) Stambia pour créer le programme Spark.
Les modèles ( templates ) peuvent être Spark Java, Spark SQL, Pyspark, etc. Ils sont donc indépendants des compétences et de l'expertise des utilisateurs. Des équipes avec des compétences différentes peuvent l'utiliser de manière cohérente et commencer à construire les mappings, puis choisir les modèles préférés pour produire du code Java, SQL, Python, R.
Une solution unifiée pour tout type de projet
Stambia est une solution d'intégration de données unifiée qui fonctionne bien avec Apache Spark et mais peut fonctionner aussi avec d'autres types de technologies.
Dans tout système d'information, il existe différents types de besoins en données provenant de diverses applications et systèmes sources, qui ne nécessitent pas nécessairement le même traitement.
Avec Stambia, différentes équipes travaillent par exemple sur différents projets : un projet d'entrepôt de données impliquant une base de données comme Teradata, un projet de streaming en temps réel avec un agent de messages comme Kafka ou un projet Data Lake sur Cloud comme AWS, GCP ou Azure utilisant le Data Storage, ndes bases de données SQL et NoSQL... Tous ces projets peuvent être gérés au sein du même outil de développement Stambia (Designer).
Grâce au mapping de données universel, tout le monde conçoit les flux de données de manière cohérente, quel que soit le type de projet ou de technologie impliqué, permettant de couvreir vos besoins actuels et futurs en matière d'intégration des données.

Stambia: une approche ELT pour laisser Spark faire le gros du travail
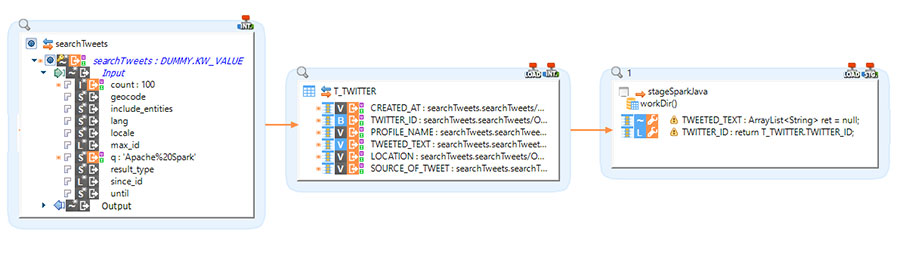
Stambia est une solution ELT ( Extraction, Chargement puis Transformation de la donnée ) qui fonctionne sur le concept de "Délégation de Transformation".
Cela signifie que les mappings que vous créez sont traduits en un code natif de la technologie sous-jacente.
Dans le cas de Spark, toutes les opérations de glisser-déposer que vous effectuez, de la source à la cible, toutes les transformations que vous écrivez, ainsi que les fonctions que vous fournissez sont traduites en un programme Spark.
Stambia est léger en terme d'installation et produira du code Spark natif tout en permettant aux utilisateurs de le gérer et le surveiller via une interface graphique facile à utiliser.
Solution facilement personnalisable et adaptable à votre disposition
Stambia en raison de sa notion de modèles ( templates ), peut être facilement personnalisé sans changer les conceptions existantes. Les modèles ( templates ) sont des objets globaux qui contiennent le code de génération du programme Spark.
Ceux-ci peuvent être rapidement personnalisés, améliorés et mis à niveau pour n'importe quelle version de Spark. Des modèles spécifiques à une version dédiée peuvent également être gérés dans votre projet.
En conséquence, chaque fois qu'il y a une nouvelle version Spark, les designs / mappings existants ne sont pas affectés. Un simple remplacement du dernier modèle ( template ) dans vos projets fait le travail de mise à niveau.
D'autre part, les développeurs eux mêmes peuvent également modifier ces modèles ( templates ) pour ajouter des fonctionnalités sans aucune contrainte, et industrialiser leurs personnalisations et innovations en les partageant entre différentes équipes.

Posséder une solution avec un coût de possession clair
Stambia fournit un modèle de tarification simple et facile à lire. Sans se concentrer sur le nombre de sources, les volumes de données à traiter, le nombre de flux, etc.
Avec une tarification simple, l'équipe Stambia travaille en étroite collaboration dans vos projets pour vous aider à comprendre et définir les phases de votre projet et à contrôler les coûts à chaque étape.

Spécifications techniques et prérequis
| Caractéristiques | Description |
|---|---|
|
Protocole |
JDBC, HTTP |
|
Structuré et semi-structuré |
XML, JSON |
| Langues supportés |
Une application Spark peut être produite pour:
|
| Connectivité |
Vous pouvez extraire ou écrire des données pour:
Pour plus d'informations, consultez la documentation technique |
|
Hadoop Technologies |
Les connecteurs Hadoop dédiés suivants sont disponibles: 1. Datawarehouse |
| Performances de chargement des données | Les performances sont améliorées lors du chargement ou de l'extraction de données via une multitudes d'options sur les connecteurs permettant de personnaliser la façon dont les données sont traitées, telles que le choix d'un chargement jdbc Spark ou des chargements de données spécifiques en base. |
| Version de Stambia Runtime | Stambia DI Runtime S17.4.6 ou supérieur |
Vous souhaitez en savoir davantage ?
Consultez nos ressources




Vous n'avez pas trouvé ce que vous vouliez sur cette page?
Découvrez nos autres ressources:
Stambia annonce son rapprochement avec Semarchy.
La solution Stambia devient Semarchy xDI Data Integration