
Stambia component for Apache Spark
Apache Spark is an open source framework for Big Data, well known for it's high data processing speed and ease of use. It provides reusability, fault tolerance, real-time processing and many more features.
Stambia component for Apache Spark is built to provide users with the ability to Automate, Industrialize & Manage your Spark projects, and be agile in your implementations.

Apache Spark: Why you need an E-LT solution?
Automate the efforts to manually code and manage Spark applications
When working on projects that deal with Big Data, Apache Spark is most oftenly preffered for huge data processing. It is being used by Data Engineers and Data Scientists to perform various data operations and analytics. A lot of coding is required when building complex applications which can become difficult to manage in a longer run.Automating this effort can be very benefitial to the organization's productivity.
On the other hand, Spark application written in Java will be hard to interpret by another team member with Python skills. A solution which can layout a consistent layer on top of this, such that the design is agnostic of the code produced in the background can change the dynamics and bring agility.
Many organizations are moving their data to cloud, some are hybrid and now a multi-cloud adoption has started, in such cases Using tools that reduce the complexities of moving your Spark application to a different environment by added automation
saves enormous time.

A complimentary solution to work with the Unified Analytics Engine
Apache Spark is known as a Unified Analytics Engine which has pre-built modules for data streaming, SQL, Machine Learning etc. All of these features needs to be supported by the a data integration tools.
This requires a solution that not only has the ability to work with all sorts of technologies, but also provide a consistent and unified platform, to be able to manage traditional as well as Big Data projects with the same skill.
As an example, project like simple data exchanges between applications, processing huge logs, real-time stream processing etc. could easily end up being designed using different tools, which can add complexities in the Information system.
Using a solution which can work in the same way when handling file systems, databases, servers, message brokers, clusters etc. Is important.
Benefit from the faster data processing and improved performance
Apache Spark is known to be 100x faster than Hadoop, due to it's query optimizer, physical engine, reduction of the number of read and writes to disc and in-memory processing.
The concept of Resillient Distributed Dataset (RDD) allows to store data in memory and persist it on disc only if needed. Spark provides high level API in Java, Scala, Python and R and has built in Machine Learning modules.
When using a data integration solution, it is important to have Spark do the heavy lifting. Often ETL tools with a propreitary engine are too heavy to be used with Spark.
Firstly, the ETL engine is of no use when you already have Spark, secondly the time spent in the administration, configuration becomes Tedious.
A solution that compliments Spark by providing more automation, felxibility and adaptibility contributes to Agility in your projects

Ability to adapt to the constant improvements in Apache Spark
Apache Spark being an open source is contantly being upgraded by the community to add new features and enhancements.
Developers needs to keep up with the latest and greatest to keep updating their applications, so as to use the new features.
In some instances, this could impact the existing processes, and would take significant effort to upgrade.
In cases such, a solution that can help in reducing this time and effort required to upgrade, can really simplify things for the Data Engineers so as to let them focus on their day to day project work
Reduce cost of ownership
Being an open source framework, Spark is also cost efficient in terms of the kind of storage that is needed when compared to Hadoop.
Due to it's ease of use and availability of various API in different languages, developers with those skills can easily pick it up and start building applications.
When using a data integration solution for your Spark project, it is important to consider the cost of purchasing and long-term ownership of the solution.
Features of Stambia Component for Apache Spark
Stambia component for Apache Spark provides an easy to use drag n drop based way of designing your Spark applications.
Some of the key benefits of using the component:
- Automation – Using the Universal Data mapper, Spark applications are generated on execution.
- Industrialization – Various types of Spark templates, written once, can be distributed to various teams
- Easy to Manage – Make changes using a GUI instead of working on a complex written code
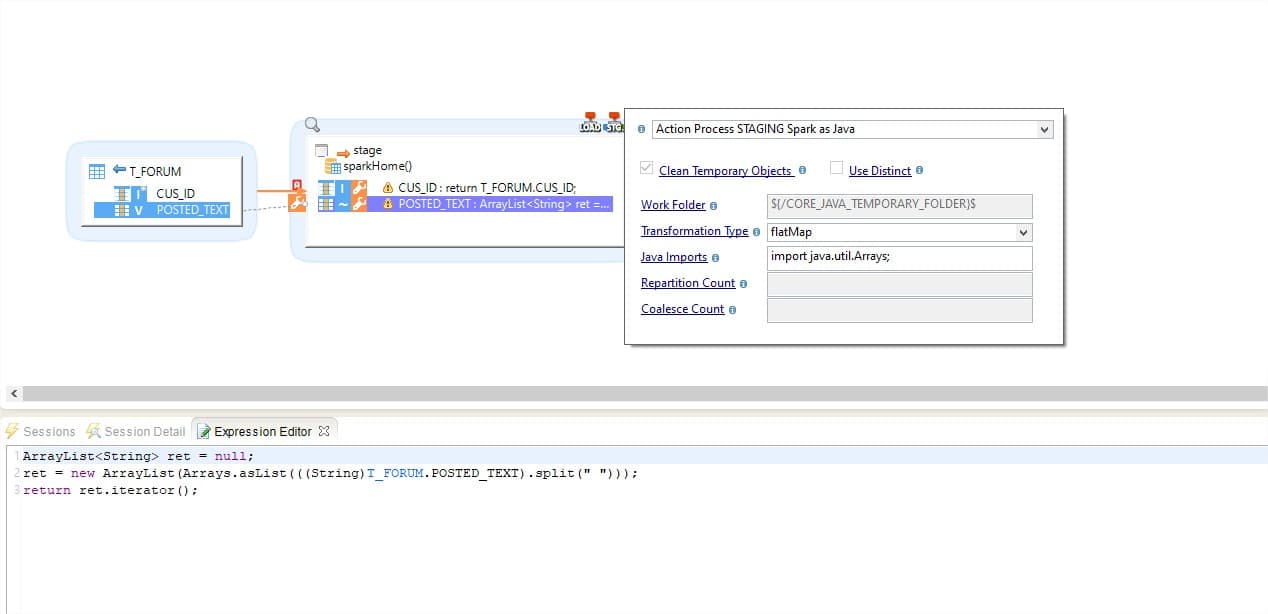
Automate with Stambia to generate Spark Applications via Drag n Drop
Stambia provides a Universal Data Mapper (UDM), which is based on a Top-Down approach. Using the GUI, you manage your data extraction from source to the Spark cluster and write Spark transformations.
Through the UDM, you provide instructions by quick configurations, which on execution are used by Stambia templates to build the Spark Application.
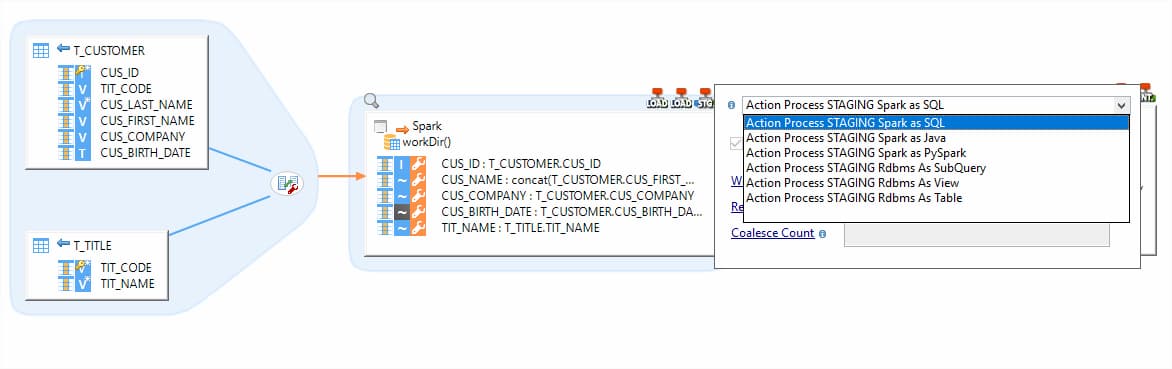
Templates can be Spark Java, Spark SQL, Pyspark etc. therefore, are agnostic of skills and expertise of the users. Teams with different skillsets can use it consitently and start building the designs and choose the preferred templates to produce Java, SQL, Python, R code.
A unified solution for any types of project
Stambia is a Unified data integration solution which works well with Apache Spark and can work with different types of technologies.
In any information system their are different kind of data needs from various source applications and systems, which doesn't necessarily need the same treatment.
With Stambia, different teams working on for e.g. a data warehouse project involving a database like Teradata, as well as a real-time streaming Project with a message broker like Kafka or a Data lake project on Cloud like AWS, GCP or Azure where you deal with Data Storage, SQL and NoSQLdatabases etc., can be managed within the same designer.
With the Universal Data Mapper, everyone designs the data flows in a consistent way, irrespective of the type of project or technology involved, which gives a greater confidence in fullfiling current and future data needs.

Stambia: An ELT approach to let Spark do the heavy-lifting

Stambia is an ELT solution that works on "Delegation of Transformation" concept.
This means that the design you create are translated to a code, native to the underlying technology.
In case of Spark, all the drag n drop you perform, from source to target, all the transformation you write, as well the functions that you provide are translated into a Spark application.
Stambia, with it's light footprint, will produce Spark code and let users manage and monitor it through an easy to use GUI.
Easily customizable and adaptible solution at your disposal
Stambia due to it's notion of templates, can be easily customized without changing the existing designs. Template are global objects that hold the Spark program generation code.
These can be quickly customized, enhanced and upgraded for any version of Spark. Dedicated version specific templates can also be maintained in your project.
As a result of this, every time there is a new Spark version, the existing designs/mappings are not impacted. A simple replacement of the latest template in your projects does the job of upgrading.
On the other hand, hands-on developers as well, can modify these templates to add features themselves without any constraint, and industrialize their customizations and innovations by sharing it across different teams.

Own a solution with clear cost of ownership
Stambia provides a simple and easy to read pricing model. With no focus on number of sources, data volumes to be handled, number of integration pipelines etc.
With a simple pricing Stambia Team works very closely in your projects to help you understand and define the phases of your project and have control over the cost at each step.

Technical specifications and prerequisites
| Specifications | Description |
|---|---|
|
Protocol |
JDBC, HTTP |
|
Structured and semi-structured |
XML, JSON |
| Languages Supported |
Spark application can be produced for:
|
| Connectivity |
You can extract data from :
For more information, consult the technical documentation |
|
Hadoop Technologies |
Following dedicated Hadoop connectors are available: 1. Datawarehouse |
| Data loading performances | Performances are improved when loading or extracting data through a bunch of options on the connectors allowing to customize how data is processed such as choosing a Spark jdbc load, or specifc data loaders from the database. |
| Stambia Runtime version | Stambia DI Runtime S17.4.6 or higher |
Want to know more ?
Consult our resources




Did not find what you want on this page?
Check out our other resources:
Semarchy has acquired Stambia
Stambia becomes Semarchy xDI Data Integration