
Stambia Data Integration
En un contexto en el que la data está en el corazón de las organizaciones, la integración de datos se convierte en un proceso clave para el éxito de las transformaciones digitales. No hay transformación digital sin movimiento o transformación de datos.
Las organizaciones deben asumir varios retos:
- Poder interconectar los sistemas de información
- Tratar de manera ágil y rápida crecientes volúmenes de datos y tipos de información muy diferentes (dato estructurado, semiestructurado o no estructurado)
- Manejar de manera adecuada tanto cargas masivas como ingestas de datos en tiempo real, con el fin de tomar decisiones pertinentes
- Tener control y dominio sobre los costos de infraestructura del dato
En este contexto, Stambia responde aportando una solución unificada para todo tipo de tratamiento del dato, la cual puede desplegarse tanto en la nube como en sitio, y que garantiza un dominio y una optimización de los costos de posesión y transformación del dato.
Para profundizar en estos puntos, consulte nuestra página ¿Por qué Stambia?
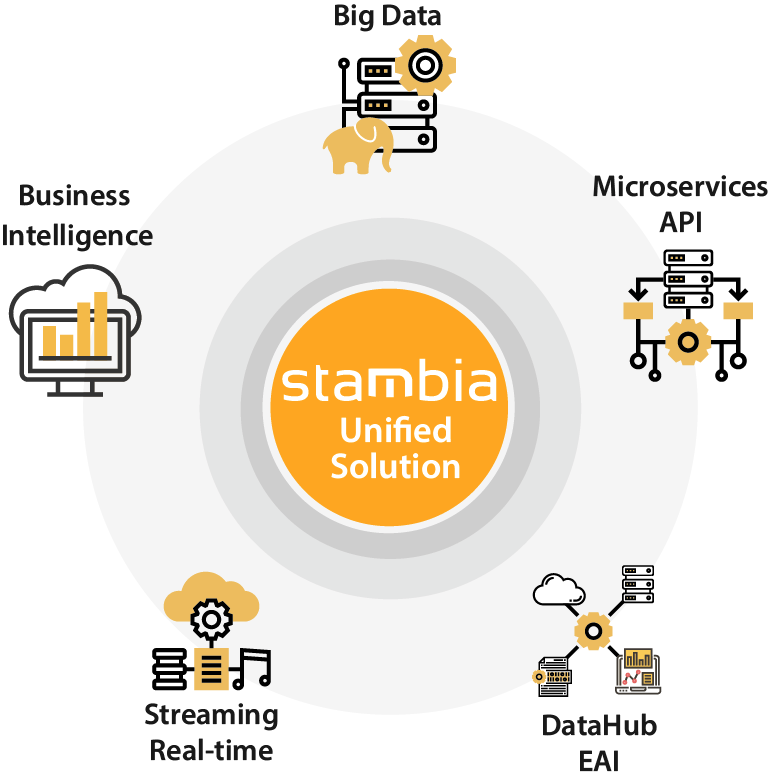
Los casos de uso de Stambia Data Integration
Los proyectos con Stambia
Con una arquitectura única y la misma plataforma de desarrollo, Stambia Enterprise permite abordar todo tipo de proyecto de integración de datos, ya sean proyectos que aborden volumetrías de datos muy grandes o proyectos orientados principalmente al tiempo real.
A continuación se muestra una lista no exhaustiva de proyectos realizables:
- Alimentación de bases de datos decisionales (datawarehouses, datamarts, infocentros), inteligencia de negocio (business intelligence)
- Proyecto Big Data, Hadoop, Spark y No SQL
- Migración de plataforma hacia la nube (Google Cloud Plateform, Amazon, Azure, Snowflake...)
- Intercambio de datos con terceros (API, Servicios Web)
- Proyecto de Data Hub, intercambio de datos entre aplicaciones (modo batch o tiempo-real, exposición o utilización de Servicios Web)
- Replicación de datos entre bases heterogéneas
- Integración o producción de archivos
- Gestión de repositorios de datos de negocio
Algunos ejemplos de arquitecturas con Stambia
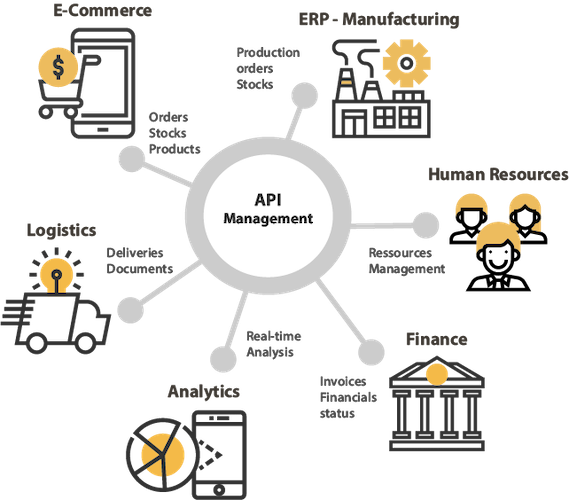
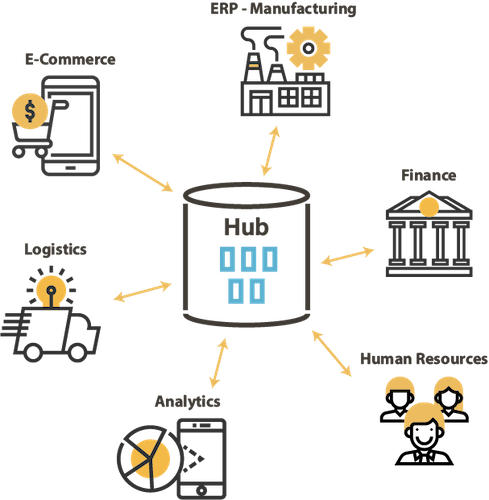
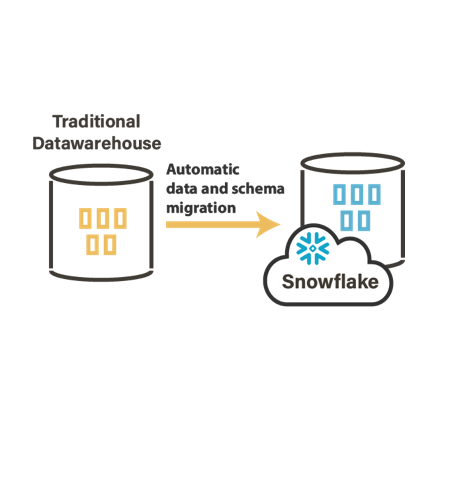
¿Cómo funciona Stambia Data Integration?
Stambia está basado en varios conceptos clave
Un Mapeo Universal
Contrariamente a los enfoques tradicionales, orientados a procesos químicos, Stambia propone una visión "universal" del mapeo de datos (mapping): toda tecnología debe poder ser alimentada o leída de manera simple, sin importar su estructura y su complejidad (tabla, archivo, Xml, Servicio Web, Aplicación SAP, ...) Es una visión Data, orientada al negocio.
Para saber más consulte la página "Mapeo Universal".

Un enfoque por modelos
El enfoque Stambia está basado en los modelos. La noción de plantillas (templates) o de tecnologías adaptativas ofrece una capacidad de abstracción y de industrialización de los flujos. Esta metodología permite ganar productividad, agilidad y calidad en los proyectos realizados.
Para saber más consulte la página "El enfoque por modelos".

Un modo ELT
La arquitectura en modo "delegación de transformación o ELT permite maximizar los rendimientos, disminuir los costos de infraestructura y tener un dominio de los flujos realizados.
Para saber más consulte la página "El enfoque ELT".

Un dominio de la trayectoria
La visión de Stambia es permitir a sus clientes dominar los costos de posesión de plataformas de integración de datos.
Esto es posible gracias al modelo enconómico de Stambia y a los enfoques tecnológicos escogidos que permiten aumentar la productividad y reducir la curva de aprendizaje.
Para saber más consulte nuestra Oferta tarifaria.
Y una arquitectura simple y ligera
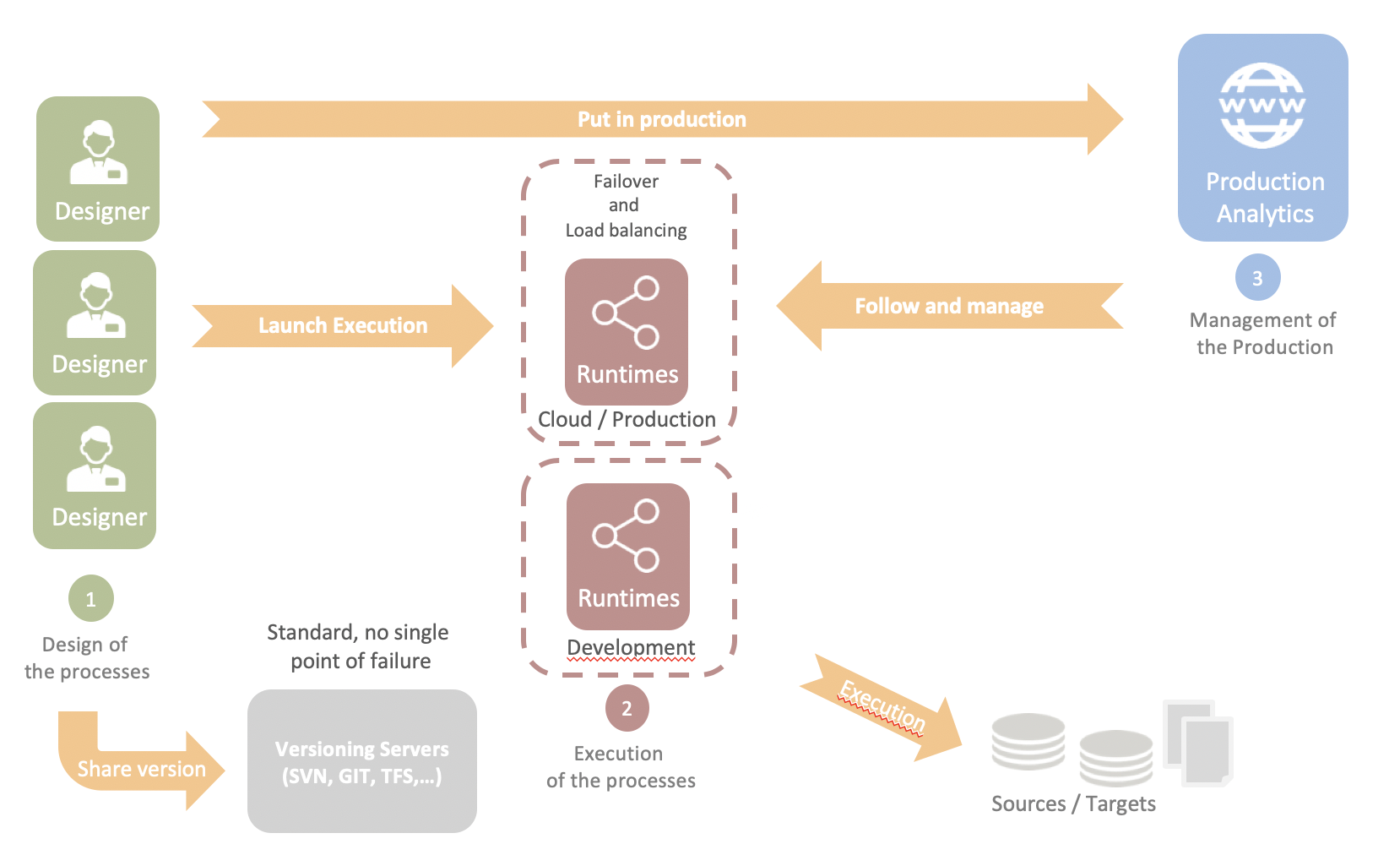
La arquitectura de Stambia Enterprise se basa en tres componentes simples:
- Los Designers son los puestos de desarrollo y de prueba. Los Designers se basan en una arquitectura Eclipse que facilita el compartir así como una gestión flexible de los desarrollos y de los proyectos en equipo.
- Los Runtimes son los procesos que ejecutan los trabajos (jobs) en producción. Se basan en una arquitectura Java que facilita su despliegue en sitio o en la nube. Son compatibles con Docker y las arquitecturas Kubernetes.
- Stambia Analytics es el componente web que permite la puesta en producción (despliegue, parametraje y planificación) y el seguimiento de trabajos (job tracking), así como el pilotaje de diferentes runtimes.
Especificaciones y prerrequisitos técnicos
| Especificaciones | Descripción |
|---|---|
|
Arquitectura simple y ágil |
|
| Conectividad |
Usted puede extraer los datos de:
Para más informaciones, consulte nuestradocumentación técnica
|
| Conectividad técnica |
|
|
Características estándar |
|
| Características avanzadas |
|
| Prerequisitos técnicos |
|
| Despliegue Cloud (en la nube) | Image Docker disponible para los motores de ejecución (Runtime) y componentes de Production Analytics |
| Estándares soportados |
|
| Lenguaje de Scripting | Jython, Groovy, Rhino (Javascript), ... |
| Software de control de versiones | Cualquier plugin soportado por Eclipse: SVN, CVS, Git, ... |
| Migrar desde | Oracle Data Integrator (ODI) *, Informatica *, Datastage *, talend, Microsoft SSIS * posibilidad de migrar de manera transparente (seamless) |
¿Desea saber más?
Consulte nuestros diferentes recursos




¿No ha encontrado lo que deseaba en esta página?
Consulte otro de nuestros recursos
- [Tecnología] El Mapping Universal Stambia
- [Tecnología] El enfoque ELT
- [Tecnología] El enfoque por modelos
- [Tecnologia] El concepto de plataforma adaptativa
- [Solución] Comprenda la arquitectura Data Hub
- [Producto] Componente Salesforce
- [Producto] Publicar y consumir API y Microservicios
- [Producto] Stambia componente para Big Data Hadoop
Stambia anuncia su fusión con Semarchy the Intelligent Data Hub™
Stambia Data Integration se convierte en Semarchy xDM Data Integration