
Stambia para las bases de datos relacionales (SGBDR/RDBMS)
Stambia proporciona componentes específicos para todos los tipos de bases de datos relacionales.
Con la ayuda de estos componentes, usted puede acceder a las bases de datos para leer, escribir y efectuar transformaciones complejas.
Gracias a su mapeo (mapping) universal, Stambia le ayuda a crear oleoductos (pipelines) de integración que generan guiones (scripts) SQL nativos específicos a cada tecnología..
Bases de datos relacionales: casos de uso y prerrequisitos
Utilice un enfoque ELT para maximizar el rendimiento
Los ETL, en su época, eran necesarios debido a la incapacidad del motor de la base de datos para realizar transformaciones complejas.
Las bases de datos relacionales en el transcurso de los años han mejorado de diferentes maneras: proporcionando funcionalidades más optimizadas para la gestión de grandes volúmenes de datos, así como operadores complejos sobre estos conjuntos de datos.
Por lo tanto, el motor de base de datos es ahora más eficiente que nunca.
Trabajar con SGBDR analíticas avanzadas requiere recurrir a herramientas de carga nativas y al uso de funciones avanzadas y específicas para estas bases de datos.
Con un motor de base de datos mejorado y robusto, la adopción actual de prácticas ELT mejora el rendimiento y ofrece una mayor flexibilidad en la implantación de oleoductos de integración: Procesamientos paralelos nativos y robustos, manipulación de tipos de datos más recientes: JSON, SPATIAL, CSV, etc.
Y numerosas funcionalidades adicionales pueden ser explotadas en la construcción de desarrollos de integración.

Enfoque universal pero específico a cada tecnología de base de datos
El sistema de información de cada organización utiliza por lo menos un sistema de gestión de base de datos relacional (SGBDR) para manejar los datos de la empresa.
Estas bases de datos pueden manejar una aplicación o pueden ser utilizadas como almacén de datos (data warehouse) con fines de análisis y generación de reportes.
En ciertos proyectos, las SGBDR han sido utilizadas para manejar arquitecturas como los Data Hub.
Con sistemas de información que utilizan bases de datos relacionales estándar como Oracle, IBM DB2, Microsoft SQL Server, MySQL, PostgreSQL, etc., es muy importante adaptarse a la manera específica en la que funcionan.
Por esto, una solución genérica no puede manejar necesidades complejas.
La solución de integración debe proporcionar componentes dedicados y optimizados para aportar los mejores rendimientos.
Por otro lado, es necesario tener un enfoque universal de gestión de tecnologías heterogéneas para mantener desarrollos simples e industrializables.
Algunos ejemplos de proyectos Cloud realizados con la solución Stambia
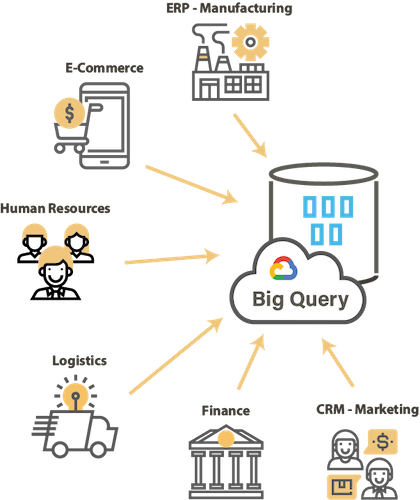
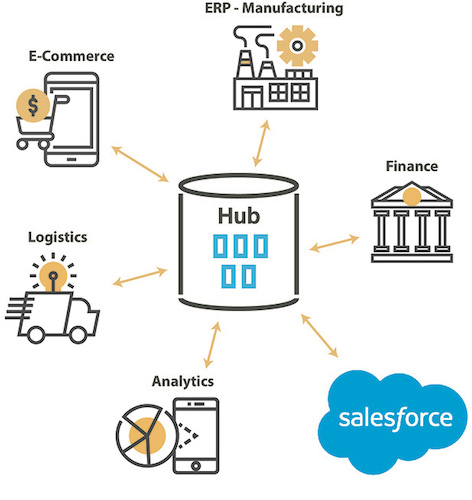
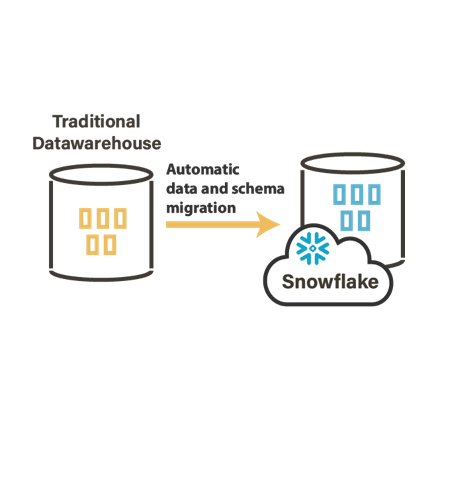
Una solución híbrida para las bases de datos en servicio en la nube
Con el advenimiento y la adopción de la nube, numerosas bases de datos relacionales están disponibles en el mercado y en los “market place” de la nube.
Estas bases de datos ofrecen las mismas funcionalidades con un modelo de pago por uso. Migrar los datos hacia bases de datos en la nube, integrar los datos cotidianos de diversos sistemas fuente hacia una base de datos en la nube, trabajar en un modelo híbrido con bases de datos en sitio o en la nube, etc, se está convirtiendo en la norma.
En este tipo de proyectos, es esencial tener una solución única, híbrida y capaz de responder de manera coherente a las diferentes necesidades en sitio o en la nube.
La agilidad y el control de los costos son también puntos clave en las arquitecturas híbridas..

Funcionalidades del componente Stambia para bases de datos relacionales
El componente Stambia para bases de datos relacionales ofrece la posibilidad de trabajar con una o varias tecnologías SGBDR y acceder, extraer, cargar y transformar datos dentro y fuera de estas bases de datos.
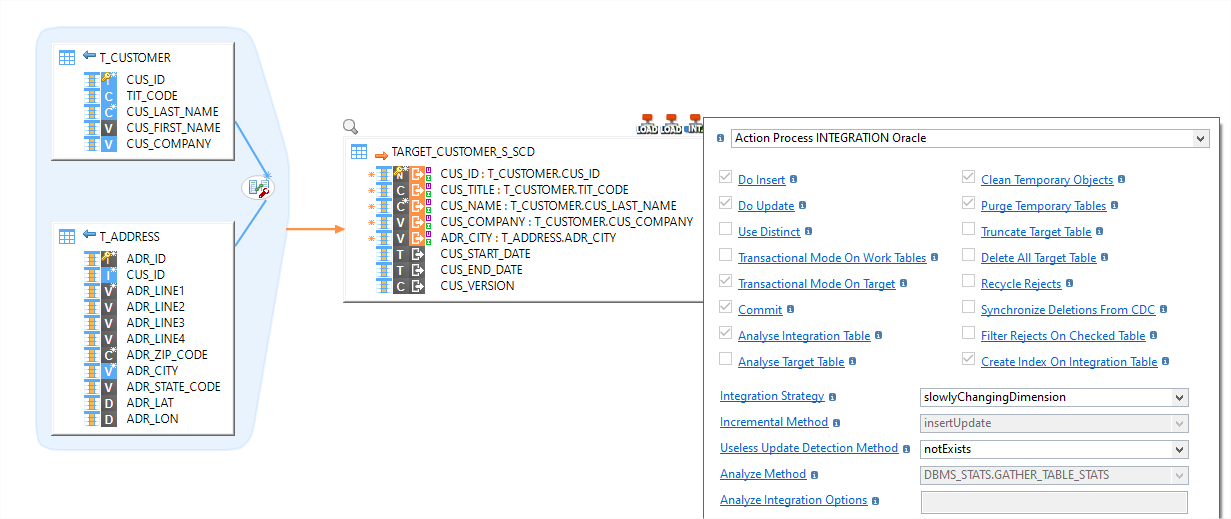
Estos componentes automatizan e industrializan una gran parte del desarrollo ya que el conjunto de etapas técnicas necesarias se agrupa en modelos técnicos llamados plantillas (“templates”).
Por ejemplo, un mismo mapeo podrá, sin ninguna modificación compleja, pasar de un modo de integración incremental (update/insert/delete) a un modo historizado (dimensiones de lenta evolución), o activar la integración en modo CDC (Change Data Capture), o incluso implementar la gestión de la calidad de datos.
Stambia utiliza JDBC como medio estándar de conexión a las bases de datos. JDBC permite un acceso nativo a todas las bases de datos sin necesidad de instalar un conector o API cliente de base de datos.
Un enfoque ELT para utilizar las funciones nativas y optimizadas de las bases de datos
Stambia implementa los principios ELT con el fin de proporcionar el mejor nivel de rendimiento de las bases de datos. El enfoque E-LT Stambia consiste en hacer las transformaciones en los sistemas subyacentes sin incorporar un motor propietario.
Las transformaciones son realizadas por las bases de datos u otras tecnologías (OLAP, sistemas operativos, etc.) en función de sus capacidades de transformación.
Stambia utilizará todos los componentes nativos de las tecnologías subyacentes (como los cargadores de bases de datos, el CDC nativo, etc.) para maximizar el rendimiento.
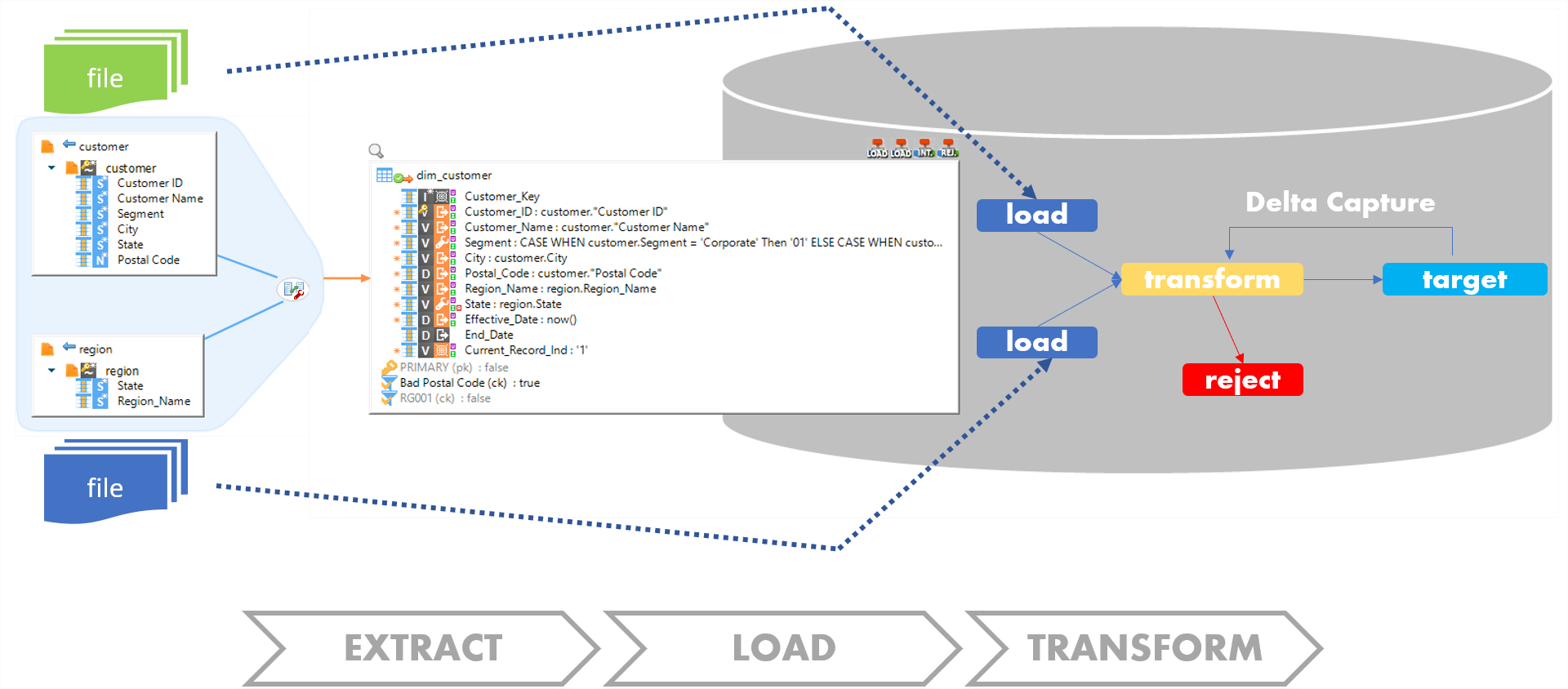
Componente dedicado para cada tecnología junto a una manera universal de desarrollar
Stambia proporciona componentes dedicados para cada tipo de base de datos relacional con el fin de responder a las diferentes especificidades que existen en estas tecnologías.
Las bases de datos relacionales se comportan conceptualmente de la misma manera pero sintácticamente son distintas entre sí, lo que significa que una solución genérica no sería suficiente para responder a todas las exigencias técnicas.
Los componentes específicos de Stambia generan código nativo.
Por ejemplo, cuando usted utiliza Oracle Database como destino, puede utilizar SQL Loader o DBLink. Cuando tiene MS SQL Server como destino, puede preferir Bulk Load o BCP.
Con el mapeo universal, los usuarios, provenientes de diferentes equipos y proyectos, conciben sus desarrollos de una manera coherente y unificada.
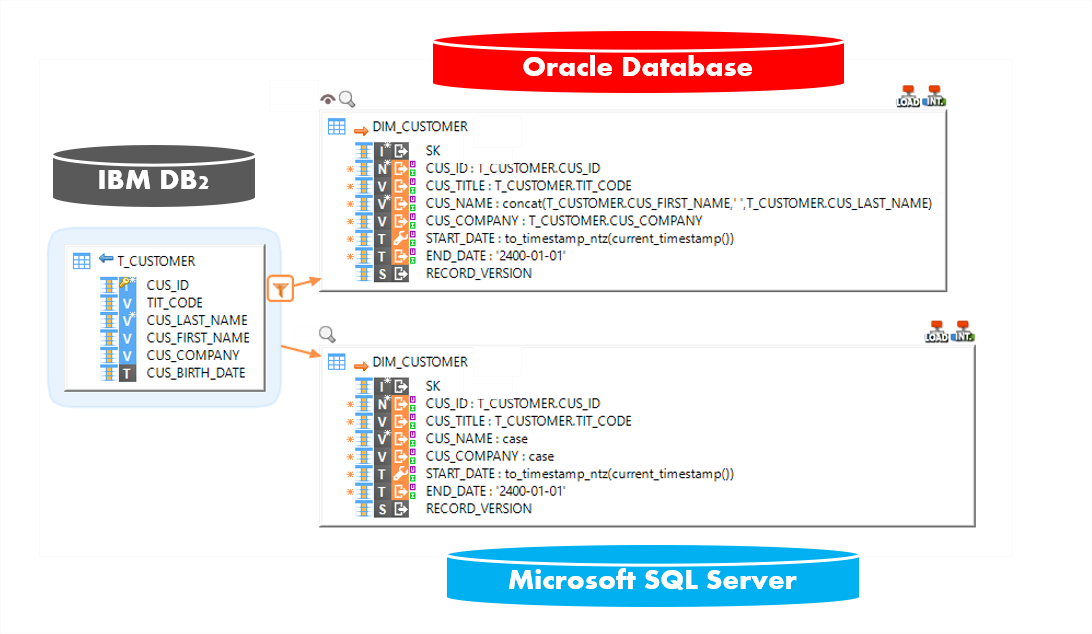
Desplegar sus desarrollos y entregables en todos los ambientes

Con los mismos componentes y utilizando la misma solución, gracias al mapeo universal, los desarrollos de integración pueden ser configurados para conectarse a una base de datos relacional en la nube (DB-as-a-service) en lugar de una base de datos en sitio (“on premise”).
Con las plantillas (templates) de replicación de Stambia, los datos pueden ser fácilmente migrados hacia la nube.
Y los mismos mapeos de datos pueden ser rápidamente configurados para apuntar hacia la instancia ubicada en la nube.
Los procesos de integración de datos pueden entonces ser desplegados sobre el “Stambia Runtime”, el cual es un componente híbrido que puede ser instalado en cualquier lugar.
Esto aumenta la productividad y la agilidad de sus proyectos.
Además, puede optimizar el costo global de transferencia de sus datos hacia la nube gracias a la noción de plantillas y con un enfoque ELT.
Usted gestiona y optimiza las transformaciones y los cálculos en la nube.
Technical specifications and prerequisites
| Especificaciones | Descripción |
|---|---|
|
Protocolos |
JDBC, HTTP |
|
Estructurados y semiestructurados |
XML, JSON, Avro |
| Características estándar | Stambia DI Runtime S17.4.7 o superior |
|
Versión de Stambia Runtime |
Stambia DI Runtime S17.4.7 or higher |
| Lista no exhaustiva de las tecnología soportadas |
RDBMS: Otras bases: Base de datos MPP: Base de datos vectoriales o In Memory: Bases de datos en la nube: Hadoop: |
¿Desea saber más?
Consulte nuestros diferentes recursos




¿No ha conseguido lo que deseaba en esta página?
Consulte nuestros otros recursos:
Stambia anuncia su fusión con Semarchy the Intelligent Data Hub™
Stambia Data Integration se convierte en Semarchy xDM Data Integration