
ETL vs ELT: Maximice sus rendimientos y reduzca sus costos de integración
"Entramos en un nuevo mundo en el que los datos pueden ser más importantes que los programas informáticos." Tim O'Reilly
La transformación digital y la explosión del número de nuevas aplicaciones ha transformado la visión del dato en el seno de los sistemas de información.
Nuevos retos han aparecido:
- La diversidad de las fuentes de datos (Nube o Cloud, SaaS, IoT: internet de las cosas, internet)
- La multiplicación de volúmenes de datos a procesar (Big Data, Redes sociales, Web)
- La aparición de nuevos tipos de datos (no estructurados "texto, audio, vídeo, imágenes”, no jerárquicos "NoSQL, Cluster")
¿Cómo ingerir, limpiar y transformar esta masa de datos rápidamente?
¿Cómo tener bajo control los costos de integración y preservar sus inversiones en infraestructura?
¿Por qué las soluciones ETL clásicas ya no responden tan bien a las necesidades actuales?
La solución Stambia Enterprise apuesta por un enfoque diferente, llamado de "delegación de las transformaciones" de datos, denominado también enfoque ELT.
Descubra las diferencias fundamentales entre el antiguo mundo ETL y la visión ELT.
¿Cuáles son los beneficios del enfoque ELT?

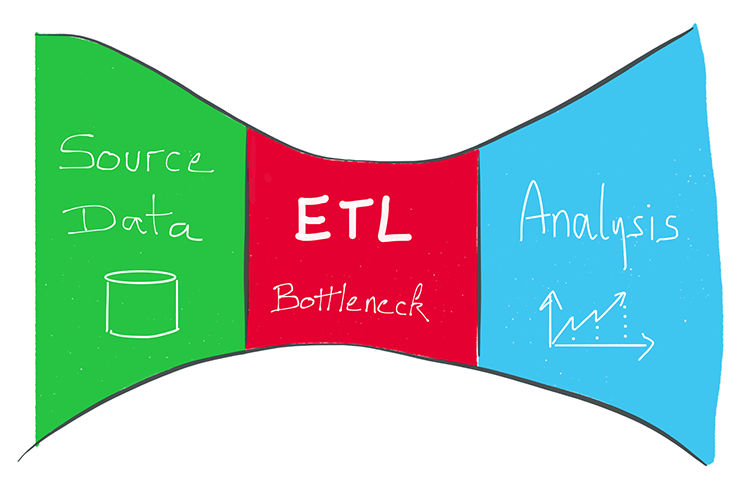
ETL tradicional de cara a los desafíos de la transformación digital
ETL: ¿Qué es un ETL?
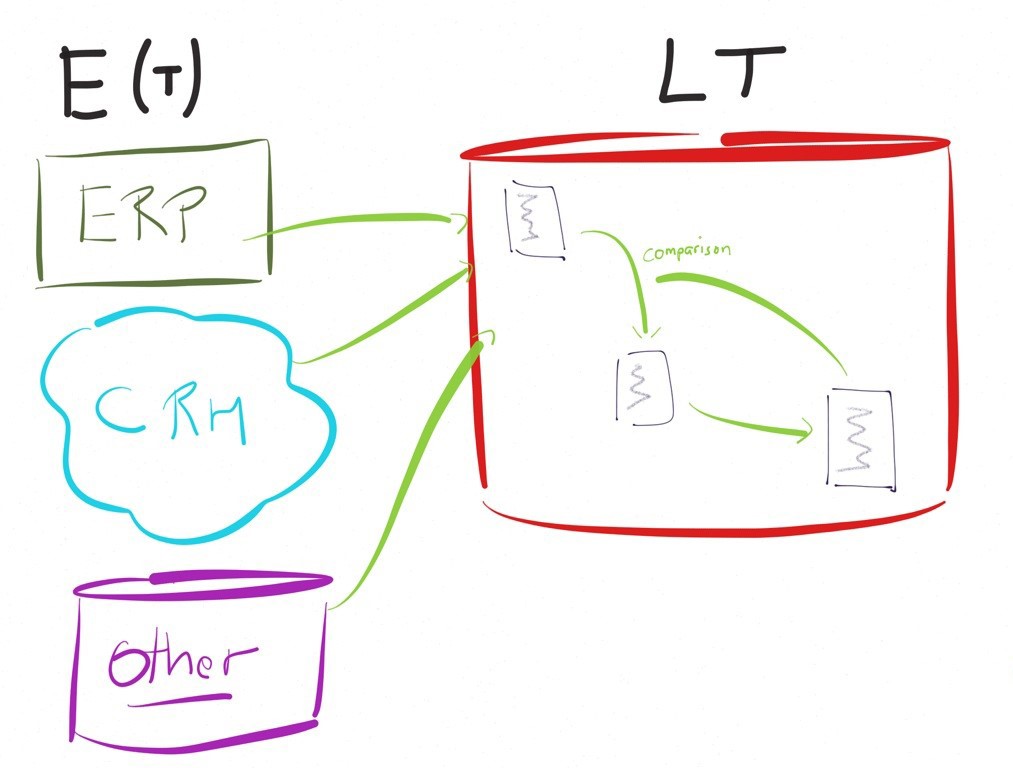
El ETL (Extraer, Transformar, Cargar / "Load") apareció en los años 80.
Se trata de soluciones informáticas que permiten responder a necesidades de transformación de datos entre fuentes y destinos: combinar y almacenar datos de diferentes tipos, provenientes de múltiples fuentes, hacia una base de datos de destino.
Las herramientas que se inscriben en esta lógica disponen en general de un motor (engine) dedicado y privativo, y son instaladas en servidores distintos.
Tienen una visión centralizada de la transformación de datos. Todos los procesamientos de la transformación se hacen por medio del motor ETL.
Podemos citar por ejemplo Informatica, Cognos decisionStream, SSIS, DataStage, Talend, Genio ...
ETL: ¿Cuáles son los desafíos de las herramientas ETL tradicionales?
"Los volúmenes de datos se multiplican más rápido que nunca. De aquí al 2020, alrededor de 1,7 megabytes de informaciones nuevas serán creadas cada segundo para cada ser humano del planeta."
Con esa cantidad de datos generados cada segundo, la necesidad de extraer, transformar y cargar (almacenar) estos datos en sistemas de terceros para sacar información útil se ha convertido en un imperativo para cada empresa.
Sin embargo, debido a la utilización de un motor de transformación dedicado, las herramientas tradicionales ETL del mercado se enfrentan a los siguientes límites para gestionar grandes volúmenes de información:
- Un efecto de cuello de botella:
- Mientras más se desarrollan flujos más cobra importancia la concentración en el motor de transformación (engine)
- Esto puede ser desventajoso en términos de rendimiento
- Esto aumenta de manera importante la demanda de tráfico de red (network)
- Este tipo de arquitectura puede revelarse costosa debido a :
- El costo generalmente relacionado con la potencia del motor de transformación (facturación al procesador, por ejemplo)
- El costo del recurso utilizado (mayor el volumen de sus datos y mayores deberán ser los recursos dedicados)
- La necesidad de localizar de manera física el motor de transformación:
- Arquitectura en la Nube: necesidad de hacer transitar los datos a través del motor.
- Architecture Hadoop: idem
30-40%: estimación del volumen de datos creados cada año
Pequeña ilustración de los límites del enfoque ETL
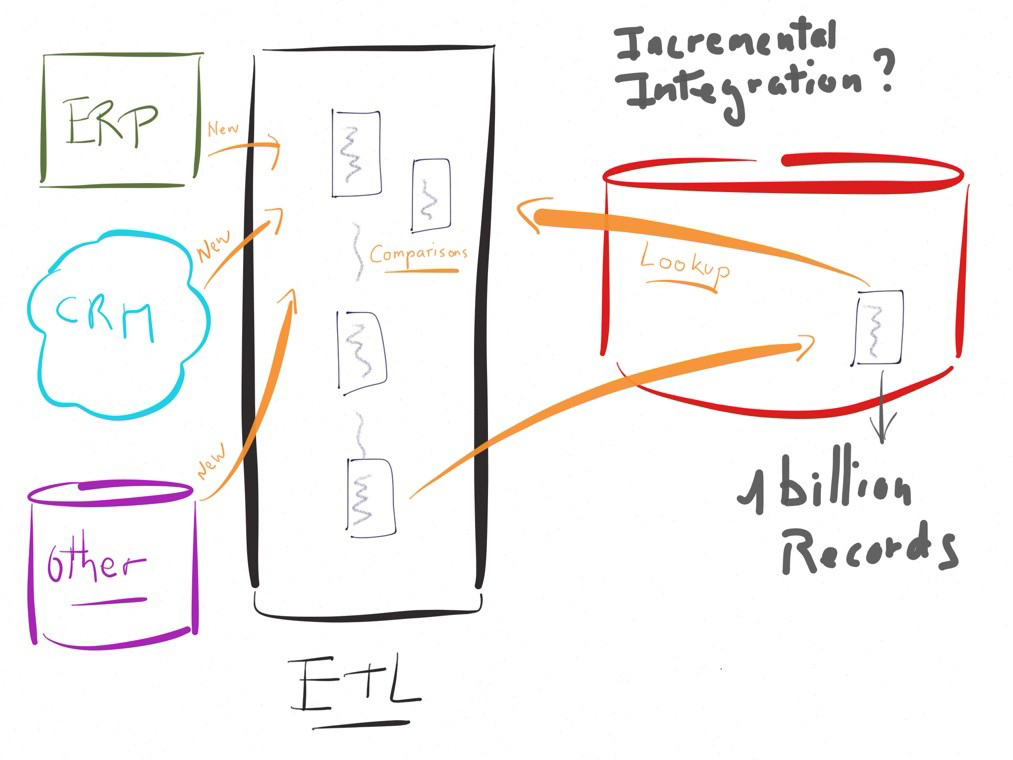
Para convencernos sobre la utilidad de un enfoque E-LT tomemos un ejemplo concreto.
Imaginemos que se presentan fallas al alimentar un sistema decisional, digamos una tabla en un destino, la cual ya contiene millones o millardos de registros acumulados en el tiempo.
La alimentación en modo incremental de este destino a partir de algunos miles de nuevas líneas en la fuente, es decir actualizando únicamente las modificaciones de la fuente desde la última ejecución, requerirá una comparación de las nuevas líneas con las líneas existentes.
En un enfoque tradicional basado en un motor de transformación, la ejecución sería similar al diagrama que se presenta, implicando funcionalidades de lookup (o equivalente) para comparar los datos.
En este ejemplo, el rendimiento se convierte rápidamente en un reto importante.
En un caso tal, los ETL tradicionales reniegan de su lógica de «motor» preconizando ejecutar instrucciones sobre las bases de datos más que sobre su sistema.
El enfoque por delegación de transformaciones, ¿qué es?
Definición ELT
El enfoque ELT (delegación de transformaciones) consiste en sacar provecho de los sistemas de información existentes dejando efectuar el trabajo de transformación a las tecnologías ya instaladas (tecnologías subyacentes)
Las transformaciones son realizadas por las bases de datos o las otras tecnologías manipuladas (cluster hadoop, cluster cloud, cubos OLAP, sistemas de explotación, etc.).
Las extracciones e integraciones de datos pueden ser realizadas por medio de herramientas nativas existentes sobre estas tecnologías.
En esta arquitectura la carga se reparte entre los diferentes sistemas: es una arquitectura no centralizada, contrariamente al enfoque ETL, el cual es centralizado.
El momento en el que se efectúa la transformación y el lugar en el que se ejecuta son los dos elementos clave que caracterizan a un enfoque ELT.
Pequeña ilustración de las ventajas de un enfoque ELT
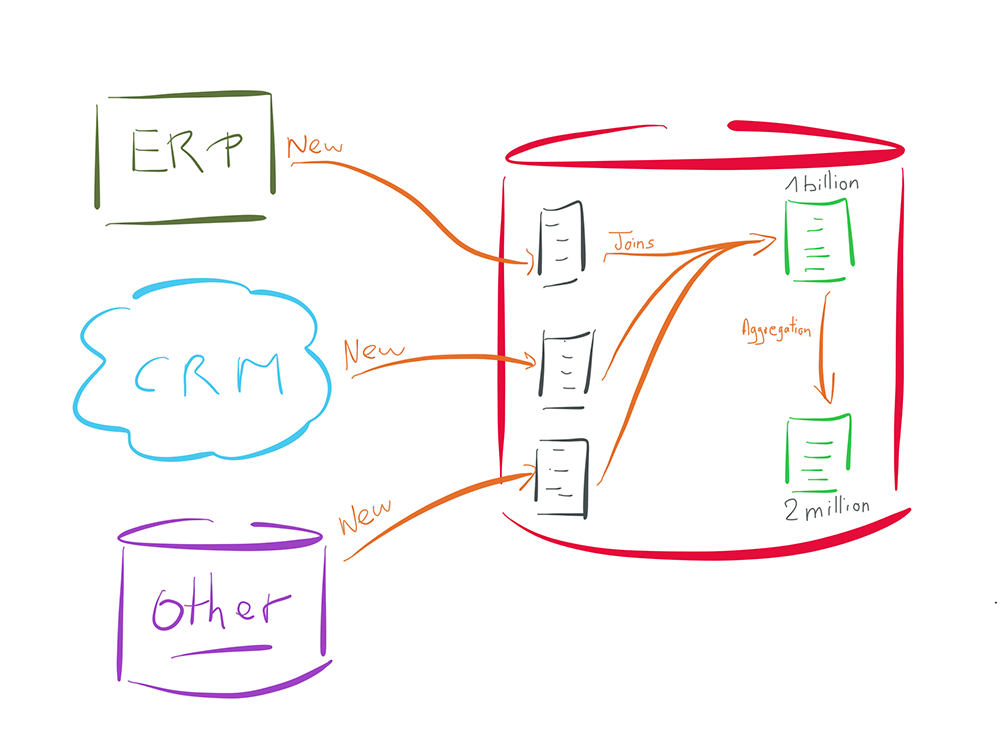
Para ilustrar, retomemos el ejemplo presentado precedentemente, pero esta vez con un enfoque ELT.
En el ejemplo precedente debíamos recolectar varios miles de "nuevos" registros en la fuente, para luego compararlos a un millardo de datos ya registrados en el destino.
El enfoque ELT va a consistir en registrar los miles de datos de la fuente en un espacio temporal, del lado de la base de destino (las tres tablas de color gris).
La comparación se va a hacer luego directamente en el seno de la base de datos de destino, sin necesidad de operaciones de lookup u otra operación que sería costosa para la base de datos.
En efecto, esta última va a utilizar sus índices u otros mecanismos internos, que están optimizados para este tipo de operación.
Así mismo, una vez que la data esté integrada en la tabla de destino (la primera tabla verde en la parte superior del diagrama), toda operación de combinación en otra tabla en el seno de la misma base de datos (la segunda tabla verde del diagrama) no requerirá de ninguna acción fuera de la base de datos (ninguna necesidad de un motor fuera del motor de la base de datos).
¿En cuáles escenarios es mejor el enfoque ELT?
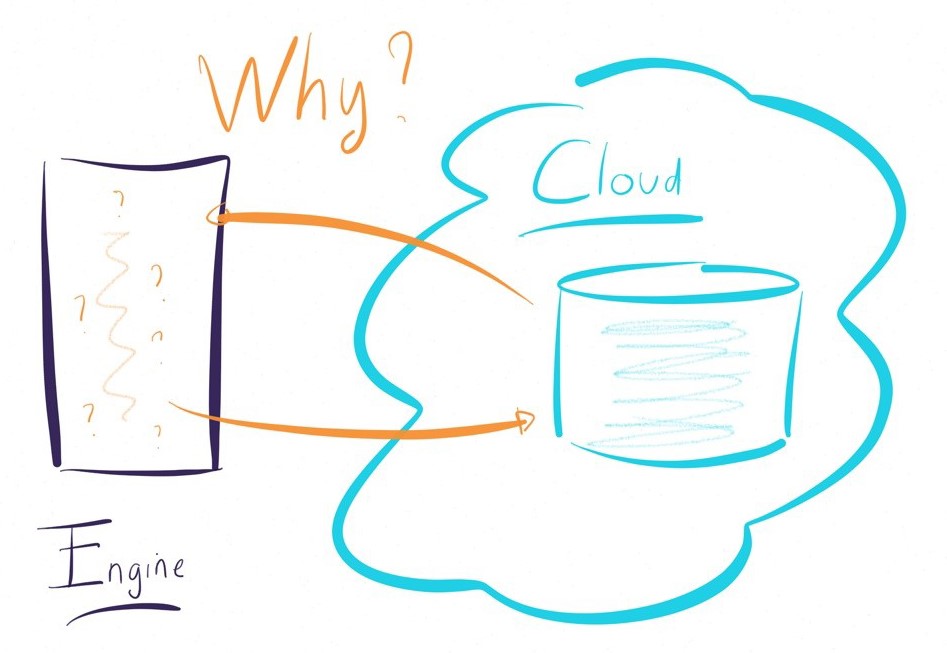
¿La arquitectura ELT es el mejor enfoque para los proyectos Cloud y las arquitecturas híbridas?
Como se ha precisado anteriormente, un enfoque ETL requiere el uso de un motor de transformación. ¿Qué pasa con las aplicaciones alojadas en la nube? ¿En dónde se ubica el motor en este caso?
El uso de la Nube rara vez se hace al 100%. Esto implica, en un enfoque ETL, la necesidad de instalar varios motores (en sitio y en la nube) para gestionar diferentes situaciones.
La situación se complica en las arquitecturas multinube (Amazon, Azure, Google…, Salesforce, Oracle…): ¿debemos entonces instalar varios motores ETL? ¿Debemos invertir en ELT específicos en la Nube, a riesgo de perder en capacidad de racionalizar y gobernar los datos?
Al contrario, la selección de un enfoque ELT funciona en todos los casos de uso, ya que no requiere la instalación de motores privativos. Esto hará trabajar las tecnologías subyacentes y tendrá una huella muy leve sobre los sistemas.

La ventaja de un ELT con respecto a un ETL para sus proyectos de Big Data
Las infraestructuras basadas en Hadoop son puestas a punto para la transformación de datos para volúmenes importantes y para casos complejos.
¿Por qué venir a agregar una capa intermedia (motor específico) para gestionar estos datos?
El enfoque ELT va a permitir delegar el conjunto de las transformaciones y la manipulación de los datos a estas poderosas plataformas como lo son Hadoop, Spark y otras tecnologías de Big Data o NoSQL.
El enfoque ELT ¿campeón en el procesamiento de grandes volúmenes de datos?
El enfoque ELT permite minimizar el uso de recursos intermediarios (servidor, disco de red …).
Este garantiza igualmente poder explotar las funciones nativas y de alto rendimiento de los entornos existentes (loader de archivo, capacidad de transformación de las bases de datos o ambientes Big Data)
El enfoque ELT evita la salida del dato de su ambiente para que sea procesada por un motor.
Tomemos el ejemplo que consiste en combinar un conjunto de datos en el seno mismo de una base de datos.
Gracias al enfoque de delegación de transformaciones ELT, esto no requerirá la salida del dato ni utilizar un motor de un tercero.
El dato se mantendrá en su ambiente, optimizando los rendimientos y el uso de los recursos de red.

Los beneficios de utilizar una solución ELT para sus proyectos de integración de datos
Resumen de las ventajas del ELT
El enfoque ELT permite:
- Maximizar el rendimiento
- Eficaz: sin tecnologías intermediarias
- Rápido: diálogo en lenguaje nativo con los actores relevantes
- Simplificar y racionalizar la arquitectura
- No intrusivo: no requiere instalar ningún sistema adicional
- Distribuido: la carga puede ser repartida en el conjunto del sistema.
- Optimizar el uso de las tecnologías ya instaladas
- Rentabilidad: la potencia disponible de los sistemas existentes es utilizada
- El conocimiento y dominio de los sistemas por parte del cliente es mutualizado
- Costo: reducir sus costos de infraestructura y capitalizar sus inversiones
- Ser naturalmente evolutivo
- Escalabilidad automática: la potencia disponible de los sistemas existentes es utilizada. Si evolucionan, el ELT saca provecho de esto.
- Despliegue rápido: la incorporación de fuentes o destinos no requiere incorporar nuevos motores. La herramienta es operacional de forma inmediata.

Beneficios del ELT Stambia
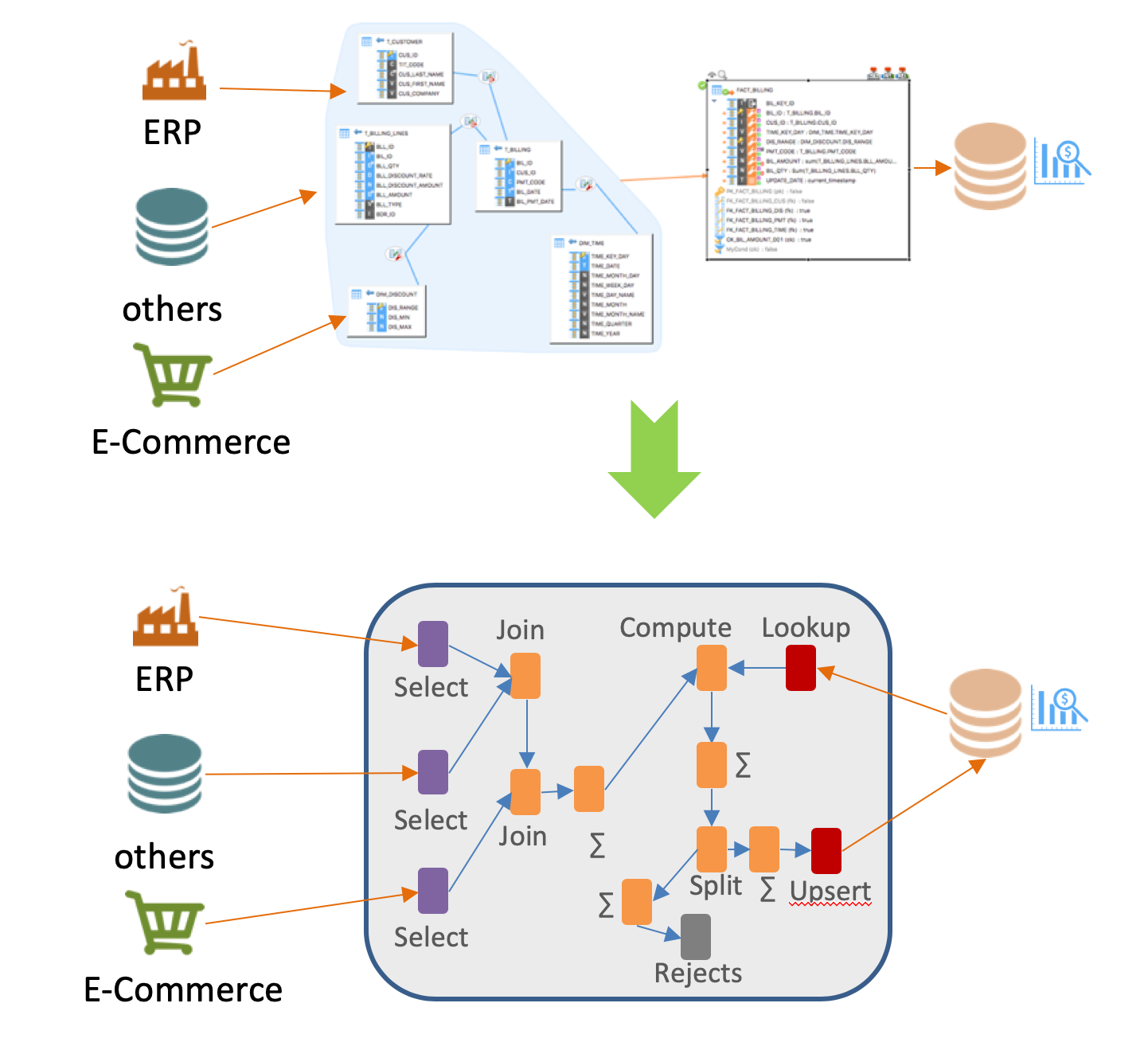
Un enfoque descendente (top down), el mapping universal para desarrollo
Un ELT sólo tiene sentido si permite simplificar el trabajo de los desarrolladores, haciendo abstracción de las tecnologías subyacentes para dar una visión más orientada al "negocio" durante el desarrollo.
En este sentido, la visión del mapeo o mapping universal de Stambia permite hacer accesible el modo ELT, sin necesidad de conocimientos técnicos avanzados.
El enfoque top down permite un desarrollo enfocándose en las reglas del negocio, y deja a Stambia generar las transformaciones sobre las plataformas adecuadas. Esta generación automática será hecha utilizando las buenas prácticas de cada tecnología, esto para garantizar altos niveles de desempeño.

Una solución completamente personalizable y autoadaptable
Ya que el enfoque ELT tiene por objetivo optimizar de la mejor manera el uso de las tecnologías existentes (bases de datos, servidores, clusters…) es importante que el ELT pueda adaptarse fácilmente y rápidamente a las evoluciones tecnológicas.
El mundo informático evoluciona rápidamente, las innovaciones no dejan de aparecen con frecuencia sobre las plataformas tecnológicas.
Adaptarse rápidamente sólo es posible si se prevé una plataforma ELT para esto.
Stambia es una plataforma en gran medida adaptable que no requiere la intervención del desarrollador para evolucionar. Los clientes o aliados pueden reaccionar rápidamente a necesidades específicas.
Para saber más: consulte nuestra página sobre el enfoque por modelos así como nuestra página sobre el concepto de plataforma adaptativa.
¿Desea saber más?
Consulte nuestros diferentes recursos



¿No ha encontrado lo que deseaba en esta página?
Consulte otro de nuestros recursos
- [Tecnología] El enfoque por modelos
- [Tecnologia] El concepto de plataforma adaptativa
- [Tecnología] El Mapping Universal Stambia
- [Solución] Comprenda la arquitectura Data Hub
- [Producto] Componente Salesforce
- [Producto] Publicar y consumir API y Microservicios
- [Producto] Stambia componente para Big Data Hadoop
Stambia anuncia su fusión con Semarchy the Intelligent Data Hub™
Stambia Data Integration se convierte en Semarchy xDM Data Integration