
Stambia componente para Big Data Hadoop
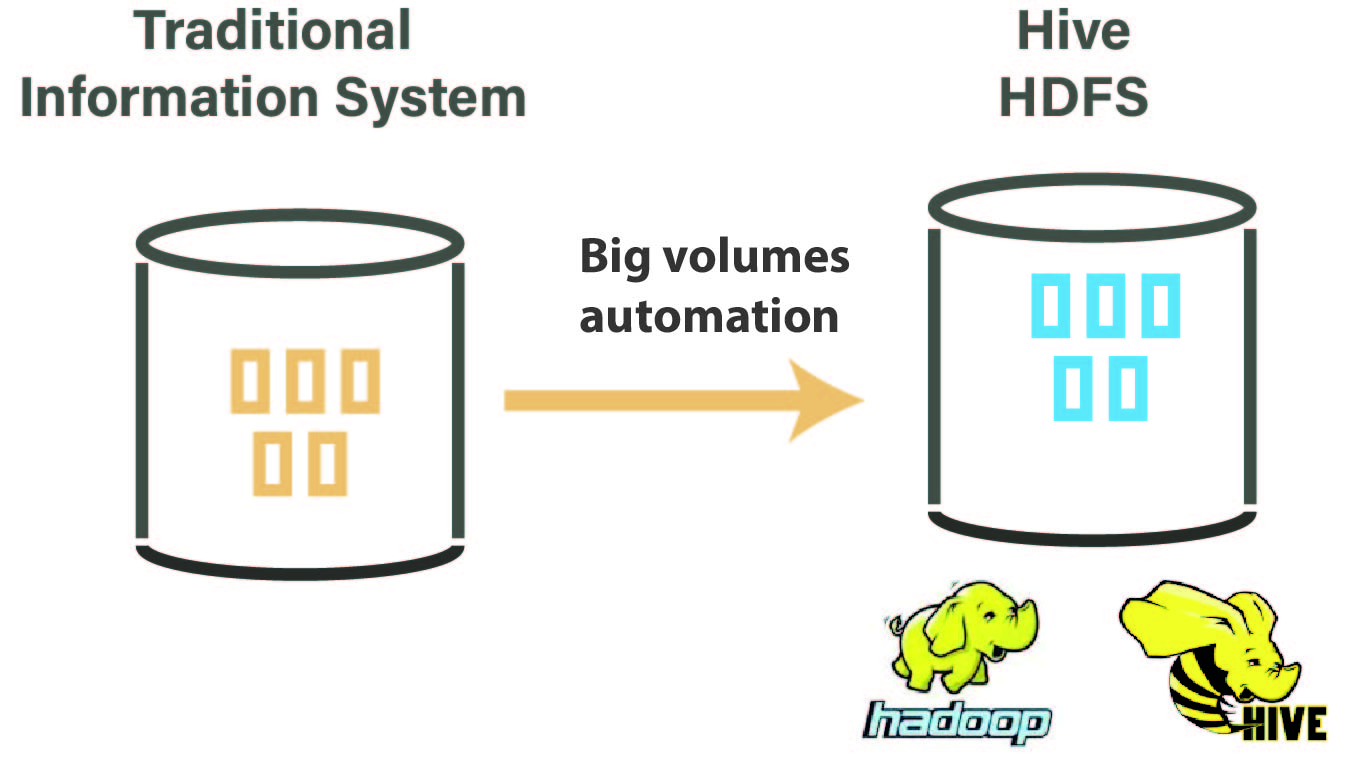
Apache Hadoop es un framework open source de almacenamiento distribuido y de procesamiento de gran cantidad de datos en clusters de computadoras. El ecosistema Hadoop consiste en una colección de programas, cada uno de los cuales responde a una necesidad específica. Los principales son: HDFS, HBASE, Hive, Impala, Sqoop y muchos otros
La integración de datos en el ecosistema Hadoop es adoptada generalmente para gestionar grandes volúmenes y una gran variedad de datos. La utilización de herramientas apropiadas para este fin es esencial para una implementación exitosa.

Adoptar Hadoop: los puntos clave
Los desafíos con Hadoop
Numerosas empresas tienen dificultades para migrar a plataformas basadas en Hadoop. A continuación, algunas razones de esto:
- Falta de herramientas que permitan reducir la elaboración manual de código así como la redundancia de esfuerzos necesarios para implementar el proceso de integración
- Una curva de aprendizaje más larga para el equipo existente, en particular en relación a la formación para la plataforma Hadoop
- Incapacidad para utilizar eficazmente la plataforma a fin de reducir costos y optimizar rendimientos
- Riesgo de exposición de datos sensibles y confidenciales debido a la ausencia de procesos de confidencialidad de datos
Para superar estas dificultades, es importante seleccionar las herramientas adecuadas para llevar a buen término sus proyectos. Éstos deben reducir la elaboración manual de código y automatizar los flujos de trabajo, con el fin de simplificar la operación y el mantenimiento.

Aproveche la potencia de Hadoop

Las herramientas tradicionales, si bien proporcionan funcionalidades que permiten trabajar con la plataforma Hadoop, no fueron concebidas originalmente para procesar grandes volúmenes de datos. Éstas fueron adaptadas para proporcionar un componente ELT-izado para la integración Hadoop.
La plataforma Hadoop evoluciona de manera lineal y se hace cargo de un extenso abanico de técnicas de tratamiento analítico.
Al momento de la integración de sus datos en Hadoop, es importante utilizar una solución ELT pura capaz de sacar el mejor provecho de estas funcionalidades para obtener los mejores rendimientos.
Proyectos de Datalake basados en Hadoop
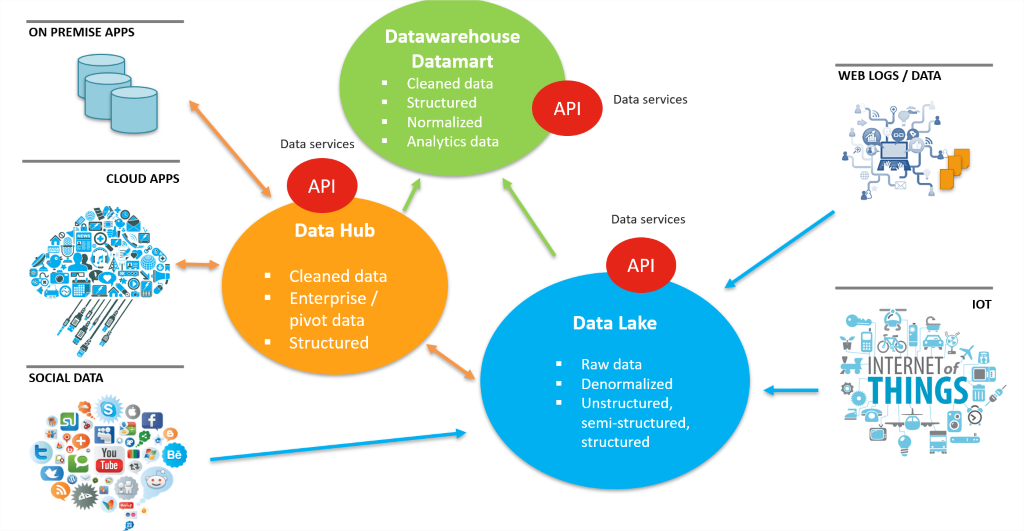
Las iniciativas Data Lake implican procesar una mayor cantidad y una mayor diversidad de datos, provenientes de diversas fuentes. Además, estos datos deben luego ser procesados y reutilizados. Hadoop se ha convertido en la plataforma más utilizada que permite a las empresas crear un Data Lake.
Con una gran variedad de programas open source en el ecosistema Hadoop, los equipos informáticos pueden configurar la arquitectura Data Lake. Una parte esencial consiste en configurar los oleoductos (pipelines) de integración que alimentan al Data Lake. Las capas de integración deben poder responder a diferentes necesidades de datos, en términos de volumen, variedad y velocidad.
La capacidad de gestionar diferentes tipos de formatos de datos, de tecnologías de datos y de aplicaciones es muy importante.
El mejor escenario es aquel en el que no hace falta apilar diferentes capas de integración sino conservar una solución única coherente y simple de gestionar.
Problema de seguridad de datos

Estando en alza la adopción de Hadoop, cada vez más organizaciones resienten la necesidad de disponer de mayores funcionalidades de seguridad, dado que el objetivo inicial era procesar grandes volúmenes de datos.
Con la introducción del modelo de distribución comercial por parte de desarrolladores de software como Cloudera, podemos ver una mayor cantidad de funcionalidades de seguridad incorporadas. Se han aportado modificaciones importantes a la autenticación Hadoop, con Kerberos, en la que los datos son cifrados en el marco de la autenticación.
La integración de datos debe no solamente sacar provecho de las funcionalidades de seguridad sino también ofrecer una gran variedad de soluciones para gestionar reglamentaciones como el Reglamento General de Protección de Datos (RGPD), el cual permite el uso de máscaras de datos en Hadoop.
TCO de sus implementaciones Hadoop
Además de la posibilidad de tratar una gran variedad de datos, una de las principales ventajas de pasar al ecosistema Hadoop reside en el costo, en comparación con los sistemas de bases de datos tradicionales.
Por lo tanto, esto debería aplicar igualmente para las herramientas de integración que serían utilizadas, con el fin de controlar el costo global de los proyectos.

Principales características del componente Stambia para Hadoop
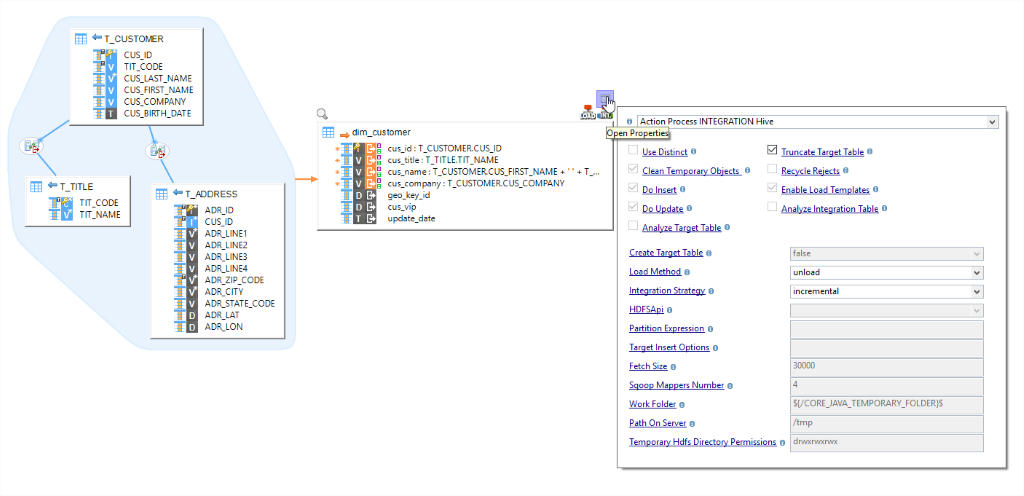
El componente Stambia para Hadoop ofrece diversas funcionalidades que permiten a los usuarios integrar sus datos y pasar fácilmente a plataformas basadas en Hadoop. No se requiere ninguna programación manual y, con el uso de Designer, los usuarios pueden realizar mapeos (mappings) de datos de la misma manera que lo hacen con cualquier otra tecnología, como en el caso del uso de una base datos, un archivo XML o JSON, archivos planos, etc.
Esto es posible gracias a los modelos Hadoop concebidos específicamente para cada programa del ecosistema Hadoop. Estos modelos reducen no solamente la necesidad de escribir código manualmente, sino que también permiten hacer evolucionar con el tiempo el proceso de integración.
-
HDFS – Es muy importante automatizar el proceso de transferencia de grandes volúmenes de datos hacia el sistema de archivos distribuido Hadoop (HDFS). Con pocos ajustes, usted puede hacer esto con Stambia, con la asistencia de modelos HDFS que pueden ayudarle a desplazar datos hacia y desde HDFS. Estos modelos pueden conectarse en cualquier sistema en función de las exigencias de integración, por ejemplo: SGBDR hacia HDFS, HDFS hacia Apache Hive, etc.
-
HIVE – Mapeos de diseño para desplazar los datos hacia y a partir de Hive de la misma manera que usted lo haría en el caso de un SGBDR. Efectúe operaciones HiveQL y seleccione opciones de modelo rápido para decidir sobre la estrategia de integración y métodos optimizados.
-
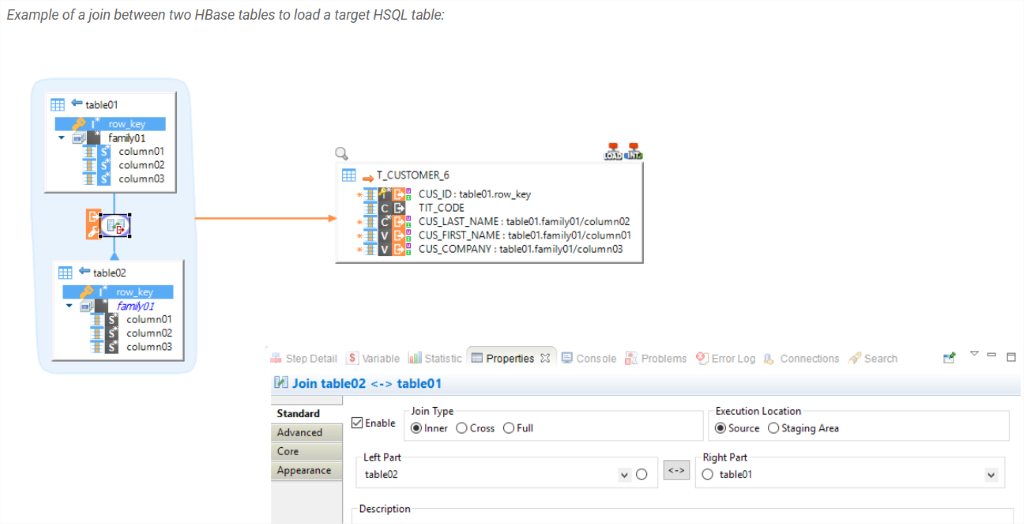
HBASE – Trabaje fácilmente con la base de datos NoSQL. No requiere conocimientos prácticos especializados para comenzar, ya que los modelos Stambia para HBASE se hacen cargo de todas las complicaciones. Como usuario, usted simplemente se encarga de arrastrar y soltar (drag & drop), escoge la estrategia de integración y extrae los datos fuera de HBASE realizando empalmes rápidos por medio de un simple arrastrar y soltar.
Aparte de los mencionados, una multitud de modelos dedicados para Sqoop, Cloudera Impala, Apache Spark, etc. están disponibles para que los usuarios puedan definir sus procesos de integración utilizando los programas apropiados de su ecosistema Hadoop.
Stambia: enfoque orientado a modelos para aumentar la productividad, el enfoque ELT para aumentar el rendimiento
Stambia, al ser una herramienta ELT pura, es conveniente para la configuración de procesos de integración en el caso de que usted trabaje con el ecosistema Hadoop. Stambia aporta un enfoque basado en modelos, que asiste a los usuarios en la automatización de numerosas etapas redundantes que implican la escritura manual de código. De esta manera, los usuarios se conectan y trabajan con sus metadatos, conciben mapeos simples y escogen ciertas configuraciones/opciones. Durante su ejecución, el código se genera automáticamente en forma nativa y se ejecuta.
Los modelos que contienen código complejo son accesibles al usuario y pueden ser modificados/mejorados en cualquier momento sin ninguna limitante.
En resumen, usted utiliza una herramienta que no solamente acelera su configuración de integración y recorta su ciclo de desarrollo, sino que también le proporciona una plataforma de integración que puede ser adaptada a cualquier cambio tecnológico o de proceso de negocio.

Stambia: una solución unificada para sus proyectos de Data Lake
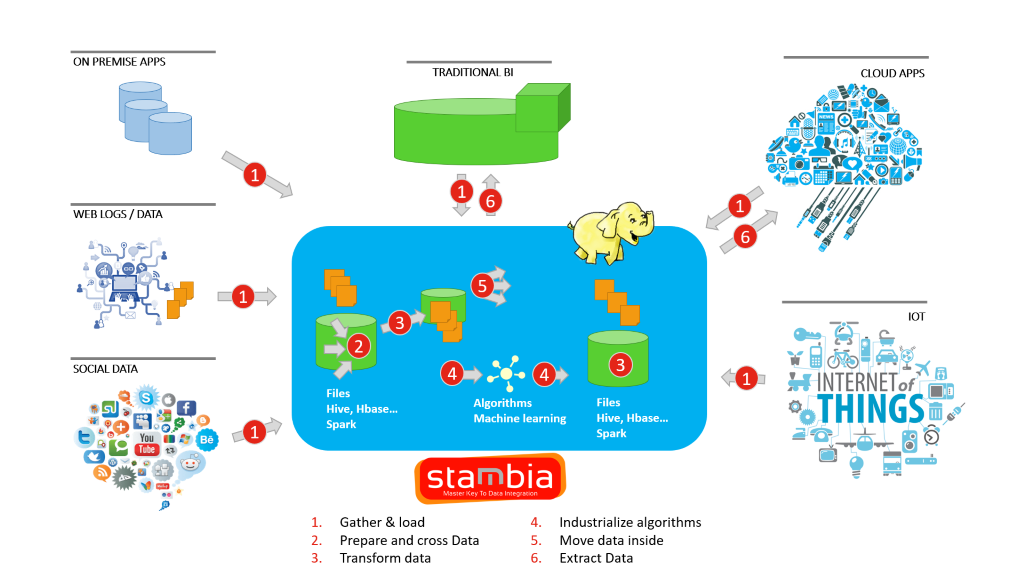
Stambia es una solución unificada que ayuda antes que nada a las organizaciones y sus equipos informáticos a construir la capa de integración sin tener que enfrentarse a múltiples programas y soluciones, con diferentes métodos de concepción y diversas implicaciones en términos de licencias.
Dado que en un Data Lake es necesario integrar diferentes tipos de datos estructurados, semiestructurados y no estructurados, utilizando una sola plataforma de integración, el acento se hace sobre la arquitectura Data Lake, más que sobre las complejidades inherentes a una integración de múltiples soluciones.
Stambia ofrece igualmente la flexibilidad necesaria para personalizar toda tecnología open source, así como otras exigencias.
Stambia: integración con seguridad
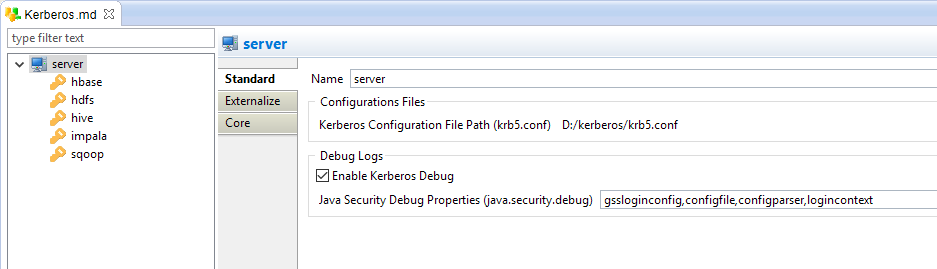
Los componentes Stambia para Hadoop se encargan de la autenticación Kerberos y son fáciles de instalar en cualquier tecnología con simplemente arrastrar y soltar. Todas las propiedades Kerberos pueden ser definidas de manera de tener un acceso securizado a los datos en Hadoop durante la integración.
Otro aspecto es la protección de la confidencialidad de los datos, o reglamento RGPD, el cual está cobrando importancia para numerosas organizaciones. Stambia tiene un componente para el RGPD, en el que los usuarios pueden anonimizar y seudonimizar sus datos.
Para saber más sobre la protección de datos de carácter personal, vea nuestro video sobre la herramienta Stambia Privacy Protect:

Hadoop es una plataforma poco costosa, por lo que la capa de integración debe serlo también
Al final, el costo de la capa de integración con Stambia en sus proyectos Big Data se mantendrá transparente y fácil de comprender. El modelo de tarifas de Stambia se mantiene simple e independiente del tipo de proyectos, volúmenes de datos, número de entornos, etc.
Como E-LT, Stambia no requiere de ningún material específico y, debido a su simplicidad de uso, la curva de aprendizaje es muy corta. Consecuentemente, en sus proyectos de Big Data basados en Hadoop, usted tiene una visibilidad clara del costo total de propiedad.

Especificaciones y requisitos técnicos
| Especificaciones | Descripción |
|---|---|
|
Protocolo |
JDBC, HTTP |
|
Datos estructurados y no estructurados |
XML, JSON, Avro (disponible próximamente) |
|
Tecnologías Hadoop |
Los siguientes conectores de Hadoop están disponibles:
|
| Conectividad |
Usted puede extraer los datos a partir de:
Para más información, consulte nuestra documentación técnica |
|
Almacenamiento |
Las siguientes operaciones pueden efectuarse en directorios HDFS:
|
| Rendimiento de la carga de datos |
Los rendimientos mejoran durante la carga o extracción de datos a través de un conjunto de opciones para los conectores, lo cual permite personalizar el procesamiento de los datos, especialmente seleccionando los cargadores Hadoop que serán utilizados Para mejorar los rendimientos, los conectores se hacen cargo del uso de diversas utilidades, tales como la carga de datos en Apache Hive o Cloudera Impala directamente a partir de HDFS, de Sqoop, vía JDBC, ... |
| Versión del Designer de Stambia | A partir de Stambia Designer s18.3.8 |
| Versión del Runtime de Stambia | A partir de Stambia Runtime s17.4.7 |
| Notas complementarias |
|
¿Desea saber más?
Consulte nuestros diferentes recursos?



¿No ha encontrado lo que deseaba en esta página?
Consulte otro de nuestros recursos
- [Tecnología] El Mapping Universal Stambia
- [Tecnología] El enfoque ELT
- [Tecnología] El enfoque por modelos
- [Tecnologia] El concepto de plataforma adaptativa
- [Solución] Comprenda la arquitectura Data Hub
- [Producto] Componente Salesforce
- [Producto] Publicar y consumir API y Microservicios
- [Producto] Componente Stambia para la nube
Stambia anuncia su fusión con Semarchy the Intelligent Data Hub™
Stambia Data Integration se convierte en Semarchy xDM Data Integration