
El componente de Stambia para BigQuery
Google BigQuery es una solución de almacén de datos de empresa (Data Warehouse) que no requiere servidor (serverless), altamente escalable, que no requiere gestión de infraestructura y que soporte los análisis para volumetría muy grandes de datos, a la escala del Petabyte.
El componente de Stambia para BigQuery permite, de manera simple y ágil, integrar y manipular los datos en BigQuery. Este aprovecha de forma nativa las características de BigQuery para:
- La gestión del almacenamiento en columna
- El procesamiento de ejecuciones paralelas masivas
- La optimización automática de los rendimientos

Diferentes casos de uso del componente BigQuery
Reducir el tiempo de puesta en el mercado
El objetivo de colocar los datos en Google BigQuery es permitir análisis más rápidos sobre volumetrías de datos más grandes.
Hacer que los datos estén accesibles para los analistas de datos y los científicos de datos (Data Scientist) se ha convertido en algo primordial. Por lo tanto, la clave para los ingenieros de datos es la puesta a disposición de los datos lo más rápido posible. Las soluciones tradicionales de integración de datos son frecuentemente complejas de instalar, configurar, mantener y para desarrollar flujos de datos.
La solución de integración de datos ideal debe funcionar en sinergia con BigQuery de manera ligera y de fácil acceso.

Migrar sus datos en local (On-Premise) hacia BigQuery
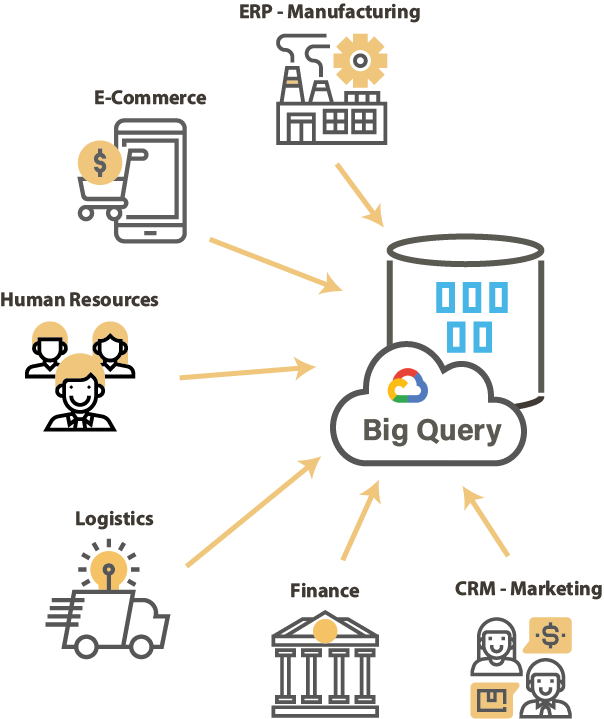
La migración de datos de un sistema en local (On-Premise) hacia un sistema en la nube (Cloud) es uno de los retos principales para el éxito global en la adoptación de sistemas en la nube. La migración debe contribuir no solamente a modernizar la arquitectura sino también a mejorar los datos.
Para esto, los expertos en migración de datos requieren un conjunto de herramientas flexible y parametrable con el fin de poder procesar rápidamente los diferentes casos de migración y mejora. En efecto, frecuentemente aparecen complicaciones durante las diferentes fases de un proyecto de migración. Disponer de una solución de integración que facilite la migración es un plus para el éxito de este tipo de proyecto.
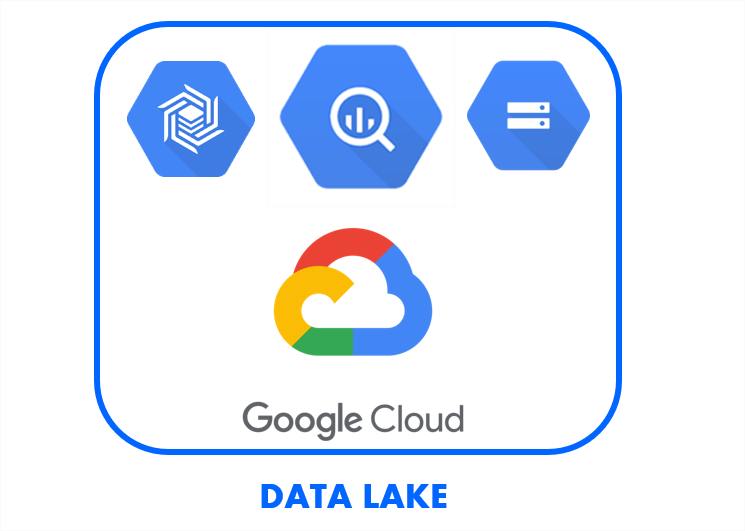
Construir un Lago de datos ( Datalake )
La plataforma en la nube de Google: Google Cloud Patform o GCP es una solución particularmente adaptada para construir un lago de datos o Datalake. BigQuery representará un rol clave. Los datos crudos pueden inyectarse en el almacenamiento en la nube de Google: Cloud Storage. Posteriormente, estos pueden ser cargados en BigQuery para constituir una capa de datos o puesta a disposición de los científicos del dato, con el fin de construir sus modelos para el aprendizaje de máquina (ML).
En un proyecto de lago de datos, es importante poder procesar diferentes tipos de conjuntos de datos provenientes de tecnologías heterogéneas, así como gestionar diferentes formatos. La capacidad de gestionar estas diferentes especificidades será la clave para el éxito del proyecto. El objetivo es reducir la necesidad de recurrir a diferentes soluciones de integración para satisfacer cada necesidad.
Tener control de los costos y reducir el costo de propiedad (TCO)

Una de las principales ventajas en el uso de BigQuery es retomar el control sobre los costos de propiedad (TCO). Los componentes implicados en un proyecto Cloud de Google debe seguir esta misma filosofía.
Sin embargo, las soluciones de integración de datos proponen frecuentemente tarifas que implican costos directos (claros) e indirectos (ocultos) que hacen difícil la comprensión global de los costos implicados.
La solución de integración de datos debe tener costos de propiedad claros y proporcionar una trayectoria legible para ayudar a definir objetivos claros a nivel presupuestario.
Características del componente de Stambia para BigQuery
El componente de Stambia para BigQuery permite contectarse rápidamente a conjuntos de datos y realizar mapeos visuales de datos medainte Drag'n'Drop. El ususario dispone de diferentes métodos de carga:
- Charga directa
- Charga mediante el alacenamiento en la nube o Cloud Storage
- Carga continua mediante Streaming
Gracias a las plantillas de Stambia para Google BigQuery, el usuario dispone de una variedad de medios para la integración, lo que simplifica el diseño y permite ganar tiempo para los desarrollos.
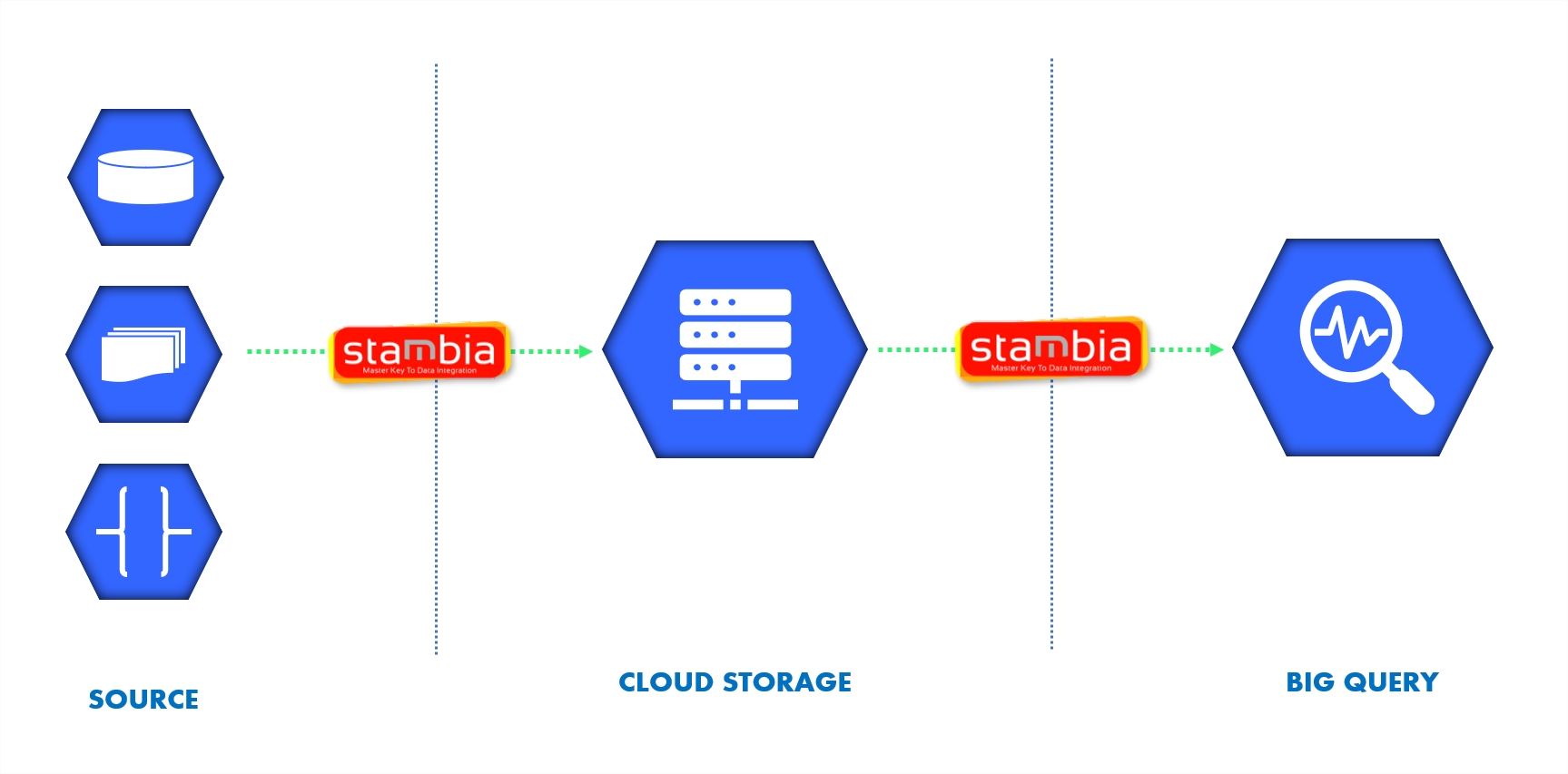
Acelerar la integración de datos en BigQuery con Stambia
El componente de Stambia para BigQuery fue concebido para simplificar la integración con una interfaz gráfica amigable, así como modelos concebidos para reducir la escritura manual de código y de scripts. Stambia propone plantillas específicamente concebidas para BigQuery. El usuario se concentra entonces en el parametraje visual de los oleoductos (pipelines) de integración mediante un simple Drag'n'Drop.
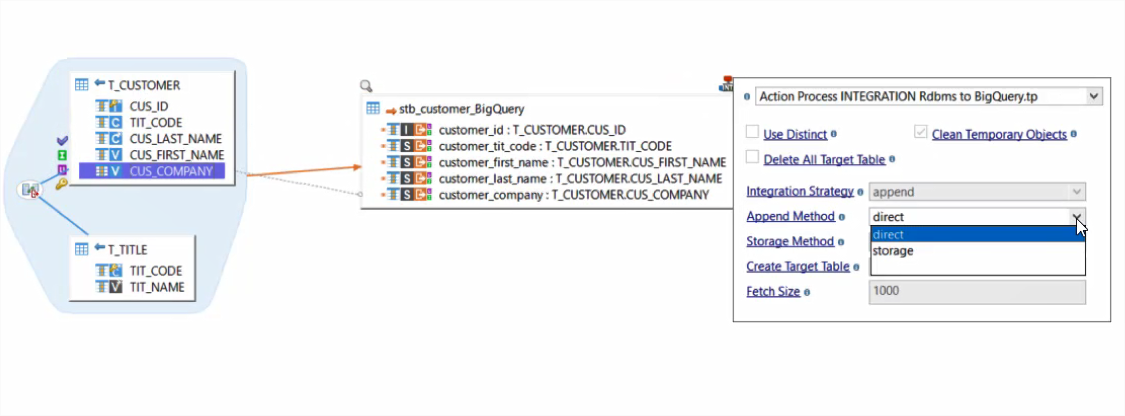
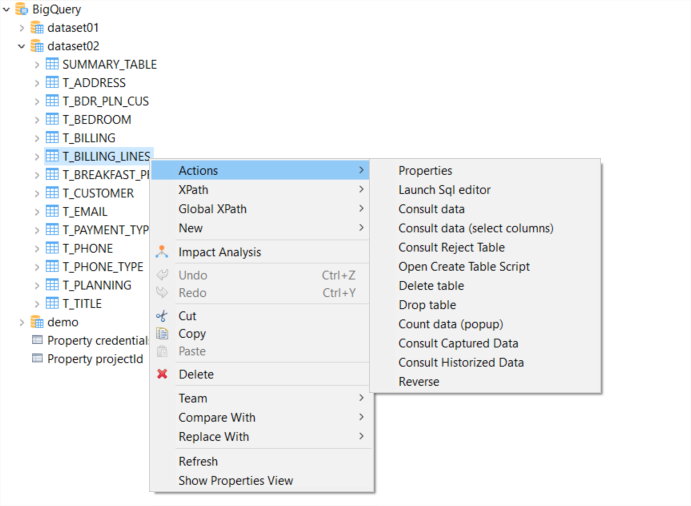
Adicionalmente, el conector para BigQuery fue concebido específicamente para sacar provecho de las capacidades nativas de BigQuery en torno a SQL. Esto gracias a las funcionalidades integradas en Stambia para procesar el SQL. Los desarrolladores trabajan de esta forma de una manera mucho más simple con BigQuery. Desde los metadatos, es posible consultar los datos, lanzar consultas, etc.
Simplificar la migración de datos de sus sistemas heredados (Legacy) en local hacia BigQuery
Para los proyectos de migración de datos, es importante poder procesar de manera simple y rápida los aspectos técnicos. En efecto, frecuentemente aparecen problemáticas durante la migración. Stambia propone soluciones personalizadas que permiten aportar la flexibilidad necesaria.
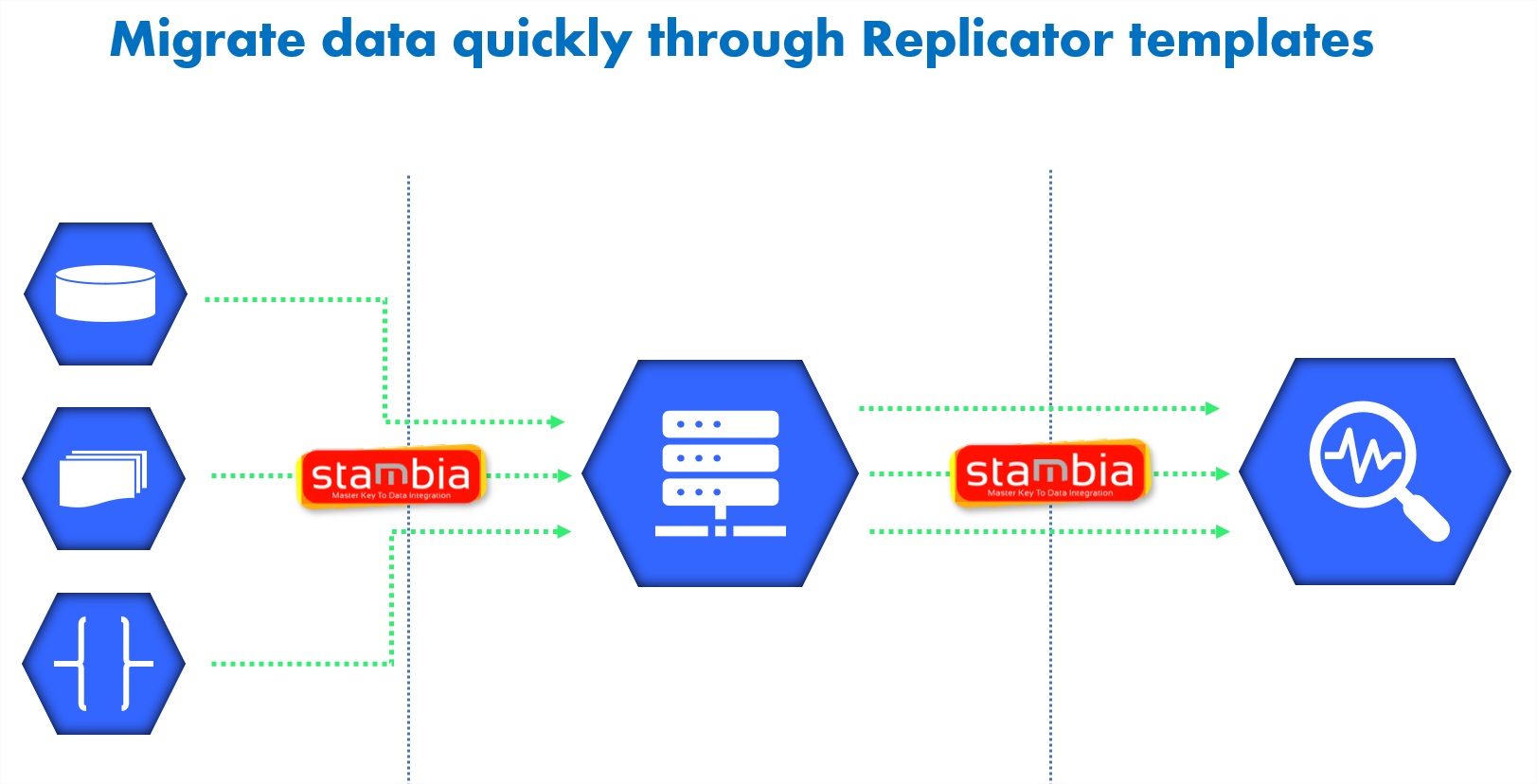
Adicionalmente, Stambia ofrece una plantilla específica de replicación de datos para BigQuery. Este "replicator" permite replicar los datos en solamente 4 etapas. La plantilla proporcionada por Stambia es totalmente parametrable para asegurar las necesidades específicas de migración.
Además, nuevas plantillas pueden ser creadas y puestas a disposición para los escenarios específicos de manera muy rápida. El equipo de proyecto puede así alcanzar los diferentes hitos con confianza y sin obstáculos
Utilice una solución de integración agnóstica de la arquitectura
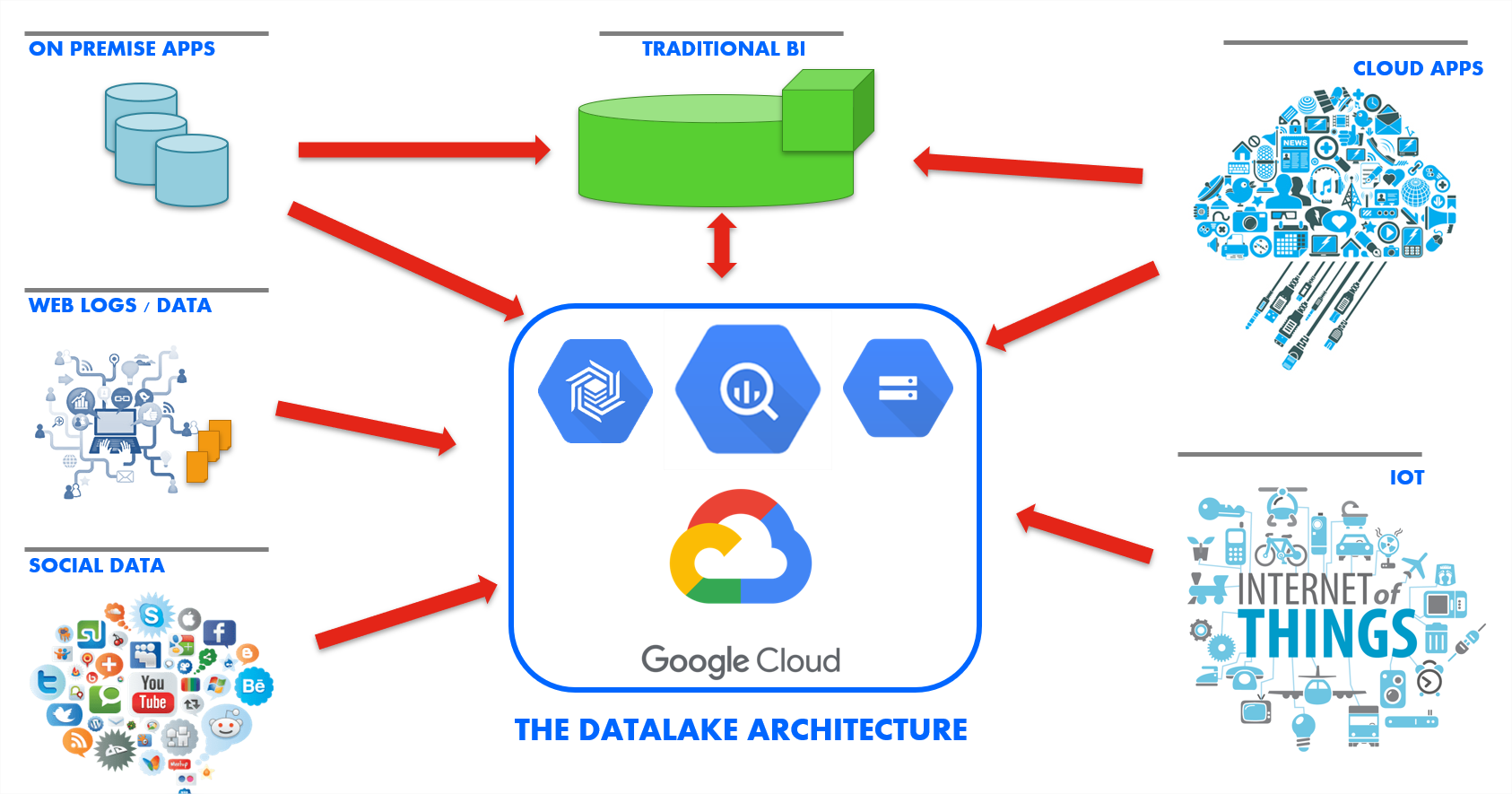
La solución unificada de integración de datos de Stambia puede funcionar con diferentes tipos de arquitecturas, de plataformas y de tecnologías. Con la misma solución, es posible iniciar simplemente un proyecto de integración de datos en BigQuery para luego evolucionar en la implantación de un lago de datos en Google Cloud Platform.
Stambia dispone de una conectividad para todo tipo de base de datos, pero además para todas las tecnologías establecidas o modernas. Stambia permite trabajar con datos estructurados o no estructurados. Esto confiere a los equipos de IT una ventaja para hacer evolucionar libremente y de manera simple la arquitectura del sistema de información.
Realizar análisis gracias a la interfaz gráfica y el Drag and Drop
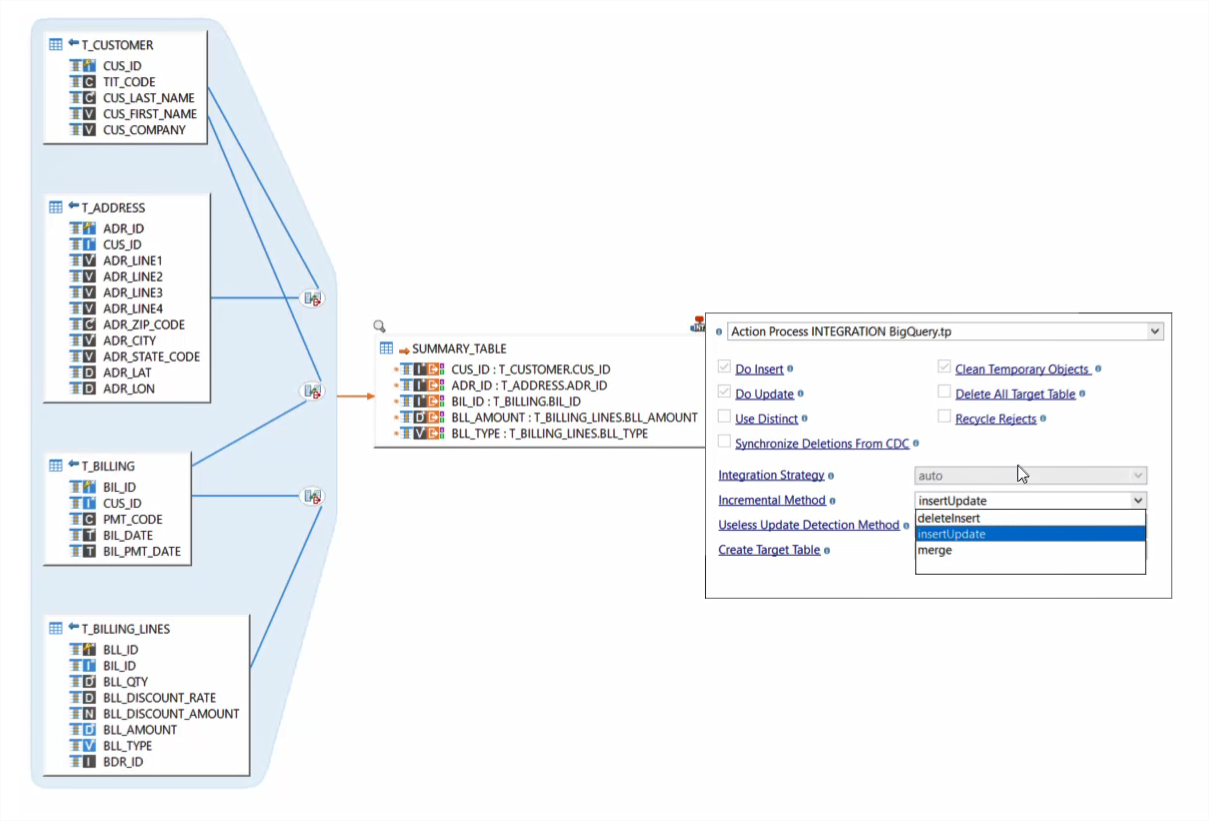
BigQuery tiene la reputación de ofrecer análisis rápidos sobre grandes volumetrías de datos. Gracias a Stambia, después de haber inyectado los datos en BigQuery, es posible realizar rápidamente las consultas de manera visual utilizando el mapeo y los Drag'n'Drop de metadatos. Todo esto en el seno de la misma interfaz. Los beneficios son numerosos, especialmente el de poder apreciar visualmente la consulta sin tener que escribir código, poder cambiar rápidamente agregando una nueva conexión o un filtro.
Por ejemplo: en caso de extracción de datos de un sistema heredado (legacy), las tablas pueden tener una integridad referencial. Cuando estas tablas son puestas en área de stage (staging) en BigQuery, es posible crear rápidamente un mapeo para conectar elementos, crear una vista no normalizada de datos y almacenarla en otra tabla de BgiQuery.
Confianza en los costos de propiedad
Stambia ofrece una lectura simple y clara de su oferta de tarifas, sin tener en cuenta los parámetros complejos a gestionar como numerosas fuentes, la volumetría de datos manipulados, el número de oleoductos (pipelines) de integración, etc.
Gracias a un modelo de precios simple, el equipo de Stambia trabaja a su lado para ayudarle a calibrar adecuadamente y tener bajo control las diferentes fases de su proyecto. Nuestros valores son las bases de su éxito: aportar valor y respetar nuestros compromisos.

Especificaciones y prerrequisitos técnicos
| Especificaciones | Descripción |
|---|---|
|
Protocolos |
JDBC, HTTP |
|
Datos estructurados y semiestructurados |
XML, JSON, Avro (próximamente) |
|
Almacenamiento |
Al momento de integrar datos en Google BigQuery utilizando un almacenamiento en la nube, usted dispone de las siguientes opciones:
Es posible escoger el método más óptimo en función de la volumetría de datos a intercambiar, de la calidad y del tráfico de la red. |
| Conectividades |
Puede extraer los datos de:
Para saber más, consulte nuestra documentación técnica |
|
Características estándar |
|
| Características avanzadas |
El componente de Stambia para Google BigQuery utiliza por defecto las consultas en modo SQL.
|
| Versión del Designer de Stambia | A partir de Stambia Designer s18.3.8 |
| Versión del Runtime de Stambia | A partir de Stambia Runtime S17.4.7 |
| Notas complementarias |
|
Al momento de integrar datos en Google BigQuery utilizando un almacenamiento en la nube, usted dispone de las siguientes opciones:
stream: Los datos son enviados directamente de manera continua al almacenamiento en la nube.
localfile: los datos son primero exportados a un archivo temporal, luego enviados hacia el espacio de almacenamiento en la nube seleccionado.
Es posible escoger el método más óptimo en función de la volumetría de datos a intercambiar, de la calidad y del tráfico de la red.
¿Desea saber más?
Consulte nuestros diferentes recursos




¿No ha encontrado lo que deseaba en esta página?
Consulte otro de nuestros recursos

Descubra en solo 40 minutos : Google BigQuery
Webinar : ¡cómo acelerar la integración de datos hacia google bigquery!
Stambia anuncia su fusión con Semarchy the Intelligent Data Hub™
Stambia Data Integration se convierte en Semarchy xDM Data Integration