
Componente ELT Stambia para Teradata
Teradata es una base de datos evolutiva (escalable) muy utilizada para procesar grandes volúmenes de datos. La plataforma Teradata Vantage ofrece una gran variedad de soluciones en torno al dato y de análisis de datos (Analytics), a través de una oferta híbrida en la nube.
El componente Stambia para Teradata fue concebido para complementar la robustez de Teradata y simplificar la integración de datos para los proyectos Analytics (Inteligencia de negocio y decisional) utilizando las soluciones Teradata.

Los procesos de integración de datos con Teradata: 6 retos
La integración de datos ágil para Teradata es necesaria
Para todo proyecto Analytics es importante escoger soluciones que mejoren la agilidad. A pesar de su apariencia simple, muchas soluciones del mercado pueden hacerse complejas con el tiempo. En consecuencia, tanto energía como un tiempo considerable son utilizados para gestionar estas herramientas.
Teradata, con su plataforma Vantage, se enfoca en proporcionar las mejores respuestas y le propone producto en la nube híbridos que simplifican su viaje hacia Analytics y la inteligencia de negocio.
En paralelo, la integración de datos debe ofrecer la misma simplicidad, la misma ligereza y facilidad de uso con el fin de que usted puede consagrar su tiempo a las exigencias en materia de datos y requisitos del negocio, y de esta manera ser más ágil en sus proyectos.

Gestione le almacén de datos tradicional y el Big Data con las mismas competencias

Con la evolución de los paisajes de datos, constatamos que cada vez más clientes utilizan diversas tecnologías y arquitecturas para responder a diferentes tipos de exigencias.
Consecuentemente, los equipos informáticos en permanencia procesan numerosos nuevos tipos de formatos de datos, de aplicaciones y de ecosistemas. Manteniendo la capacidad de procesar estos formatos, es esencial para una herramienta de integración de datos el poder integrar e intercambiar datos entre las tecnologías Teradata y Hadoop o integrar Teradata con Spark.
Todas estas funcionalidades deben formar parte de las misma solución (misma herramienta de desarrollo, misma arquitectura) para facilitar la tarea de los equipos informáticos para estos diferentes tipos de proyecto..
Despliegue la integración de datos híbrida en sitio o en la nube
La nube continúa generalizándose en la mayoría de las organización y la adopción de modelos “As a Service” (como servicio) se hace cada vez más popular. De hecho, numerosas organizaciones consideran actualmente, y algunas ya han optado por, una arquitectura multinube (multi-cloud).
Dado que ciertas organizaciones prefieren disponer todavía de ciertos datos en sitio, esta conduce a la adopción de una arquitectura híbrida. Se hace entonces necesario que los equipos informáticos puedan responder a las necesidades de integración entre estas diferentes arquitecturas.
Un elemento se hace clave: poseer una solución que se encargue de las implementaciones híbridas y multinube, por ejemplo proyectos de integración para los que usted tiene una instancia Teradata en sitio y (o) Teradata Vantage sobre AWS o Azure, así como GCP para otra necesidad.

Obtener los mejores rendimientos para la integración con Teradata por lotes masivos o en tiempo real

Cuando usted posee una solución Teradata, el uso de una herramienta de integración que proporcione un motor propietario y externo para procesar y transformar los datos no es necesariamente una buena idea.
Con funcionalidades muy robustas para la integración, el análisis y la gestión de datos, Teradata verifica todos los criterios en términos de integración (o ETL).
Una solución de integración debe sacar provecho de estas funcionalidades para mejorar los rendimientos globales de sus proyectos de análisis.
La solución debe igualmente automatizar la integración para ofrecer agilidad y flexibilidad a su desarrollo, y permitir gestionar la integración de datos por lotes para grandes cantidades de datos, así como una ingesta de datos en tiempo real para un análisis inmediato de la actividad de su organización.
El enfoque ELT es el mejor medio para optimizar su inversión y obtener los mejores rendimientos.
Utilizar una solución personalizable para Teradata Vantage
En la era en la que los algoritmos de aprendizaje automático son la nueva norma, la capacidad de proveer buenos datos es muy importante. Datos de calidad insuficiente o deficiente pueden tener un impacto sobre los resultados de estos algoritmos.
Por otro lado, la plataforma Teradata evoluciona constantemente y añade constantemente nuevas funcionalidades mejoradas para que los usuarios saquen el mayor provecho de la solución. Una solución rígida no tiene lugar en el paisaje tecnológico actual.
Consecuentemente, las soluciones de integración de datos deben ser altamente personalizables y estar listas a absorber los cambios tecnológicos y las nuevas exigencias en materia de datos.

Tomar el control y optimizar los costos de integración con Teradata Vantage
La optimización de los costos es uno de los temas críticos para la mayoría de los directores de sistemas de información (DSI), para todo proyecto, nuevo o existente, en materia de datos y análisis de datos. La complejidad de la gestión de los costos, a cada etapa del proyecto, puede depender en gran medida del tipo de herramientas utilizadas.
Cuando se habla de costo en la integración de datos, esto pasa por licencias del programa informático, de los equipos para soportarlo, de los recursos humanos para diseñarlo e implantarlo, así como por el mantenimiento a largo plazo de los proyectos. La evaluación de la solución de integración de datos debe basarse tanto en sus capacidades técnicas y sobre los gastos globales en los que usted incurrirá para utilizarla.
El estudio de los gastos no debe basarse únicamente en los costos iniciales, sino al contrario prever los gastos en los años próximos. Es un punto importante a considerar antes de comenzar cualquier selección de una solución.
Dado que ciertas organizaciones prefieren disponer todavía de ciertos datos en sitio, esta conduce a la adopción de una arquitectura híbrida. Se hace entonces necesario que los equipos informáticos puedan responder a las necesidades de integración entre estas diferentes arquitecturas.
Un elemento se hace clave: poseer una solución que se encargue de las implementaciones híbridas y multinube, por ejemplo proyectos de integración para los que usted tiene una instancia Teradata en sitio y (o) Teradata Vantage sobre AWS o Azure, así como GCP para otra necesidad.
¿Cómo funciona Stambia con Teradata Vantage?
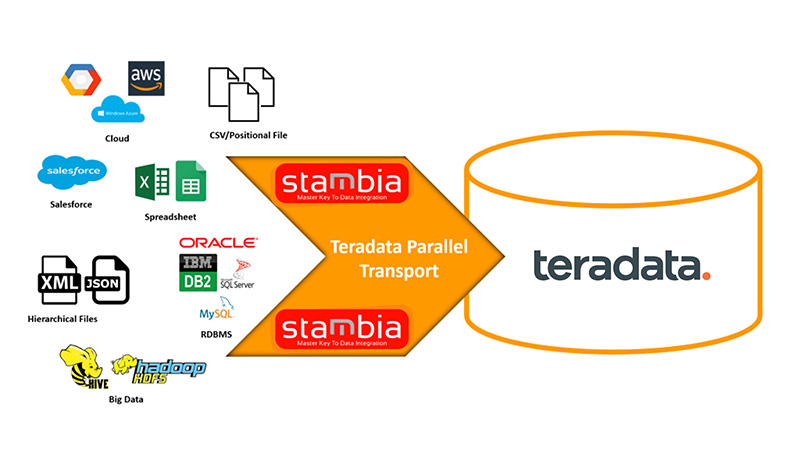
El componente de Stambia para Teradata es el mejor medio para simplificar la extracción o la integración de datos con el sistema MPP Teradata, con lo que se ofrece una mayor productividad a través de una solución gráfica fácil de usar.
Ingeniería inversa nativa de las estructuras de la base de datos Teradata
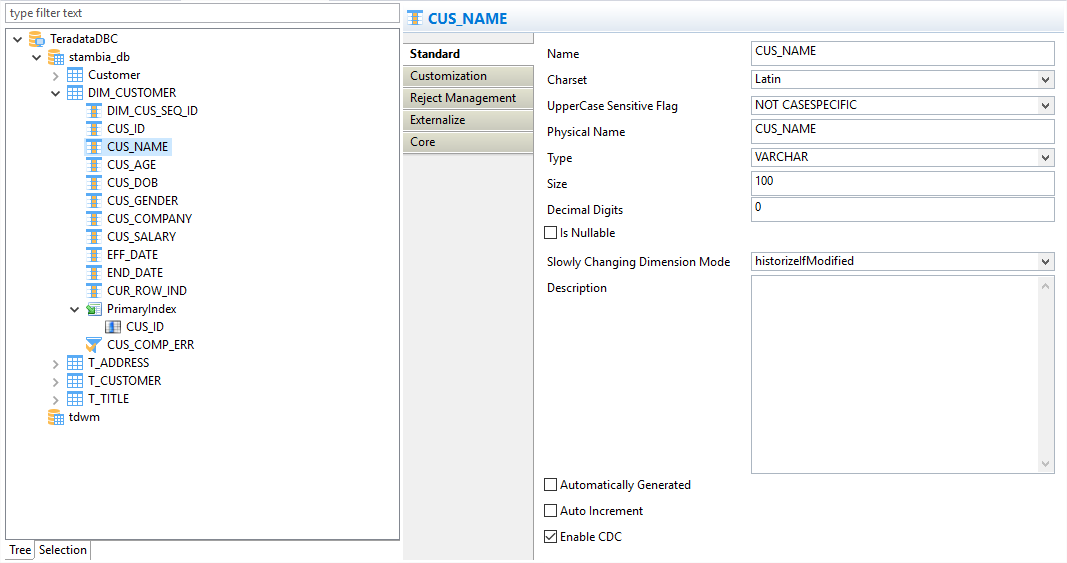
El componente de Stambia para Teradata realiza "ingeniería inversa" de todas las informaciones de la base de datos Teradata, lo cual es realmente útil durante los desarrollos para la optimización y la automatización de los trabajos de transformación de datos.
Son informaciones estándar que serán recuperadas, tales como diagramas, tablas, columnas, tipos de datos, etc., pero también informaciones específicas tales como índices primarios, UPI, etc.
Por otro lado, estos metadatos pueden ser personalizados y adaptados en función de una optimización específica para conseguir objetivos precisos, sean técnicos o de negocio.
Desarrollos orientados al negocio con Stambia: haga todo más simple y sea más productivo con Teradata
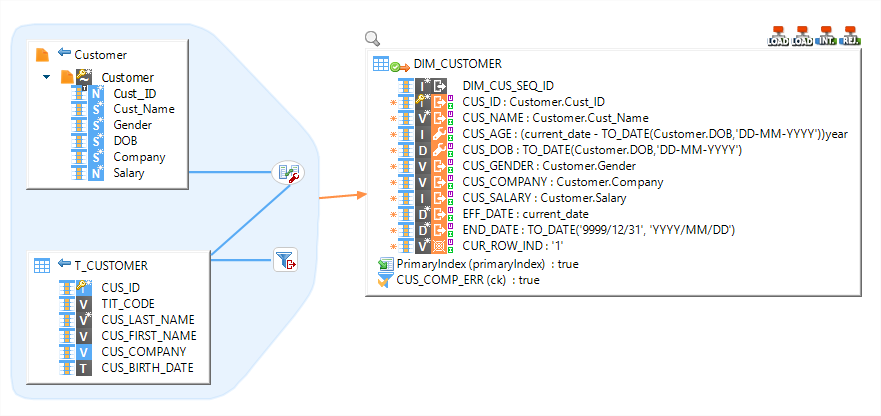
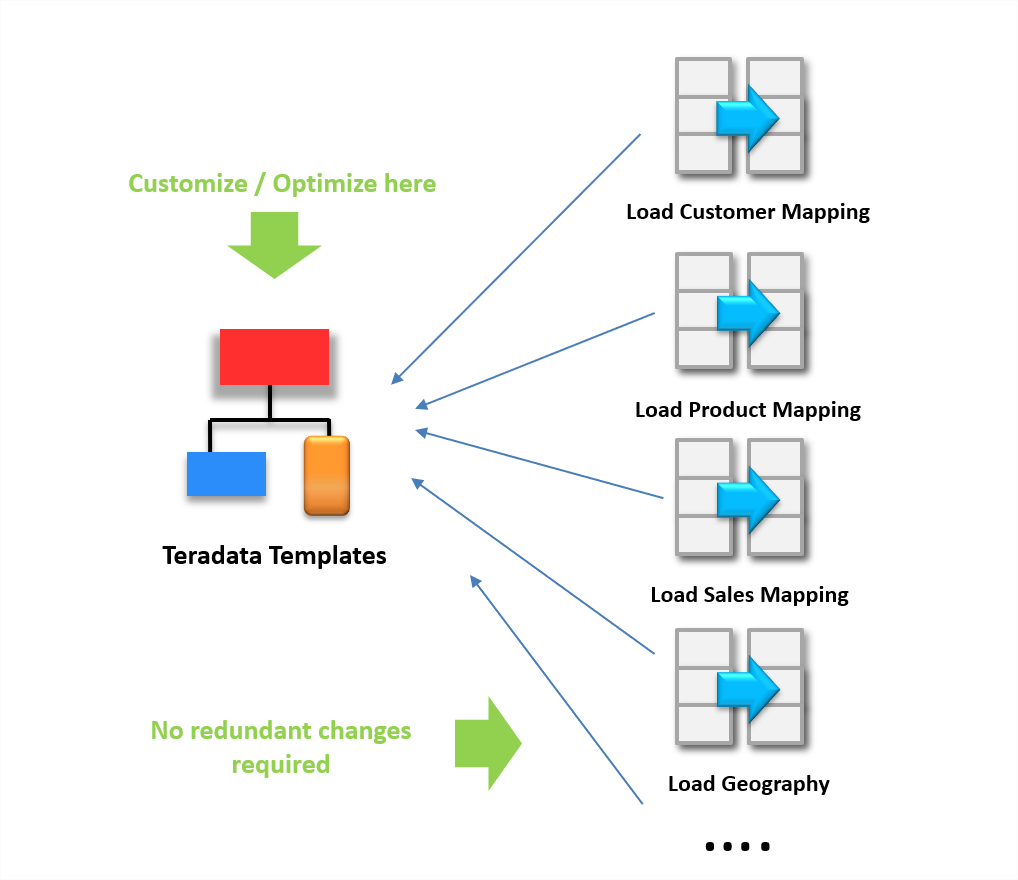
El enfoque por modelos de Stambia (a través de plantillas) permite adaptar el conector a todo tipo de proyecto.
Conéctese de manera simple a diversas tecnologías y formatos de archivo, y diseñe un mapeo simple para extraer desde la fuente, cargue en Teradata y transforme dentro de Teradata. El "Universal Data Mapper" de Stambia permite a los usuarios concentrarse en las reglas de negocio y de trabajar en un diseño muy simple y de alto nivel.
Los clientes que utilizan Teradata y Stambia confirman que el tiempo de ejecución necesario para la implantación de todo proyecto de datos nuevo es mucho más corto con respecto a lo que se hacía anteriormente.
Industrialización y automatización a través de las plantillas de Stambia
Al ser una solución de ELT, Stambia utiliza las funcionalidades nativas de Teradata para recibir, analizar y transformar datos. Es el mejor enfoque, en términos de rendimiento, para el procesamiento de grandes conjuntos de datos. Esto también reduce considerablemente la necesidad de un servidor ETL dedicado, lo cual le permite a Stambia tener una huella muy ligera sobre el sistema de información.
Por otro lado, el enfoque basado en el modelo de Stambia automatiza numerosas etapas redundantes que son realizadas en otras herramientas ETL.
Las mayores ventajas de este enfoque son:
- Facilidad en la gestión de equipos grandes en un proyecto de gran envergadura, gracias a una solución de integración coherente y automatizada
- Garantía del rendimiento esperado por un enfoque ELT
- Flexibilidad de adaptación a diversas necesidades de optimización o de personalización.
Tirez parti des optimisations Teradata intégrées
Stambia utilise des méthodes spécifiques adaptées à Teradata pour intégrer ou extraire les données.
Le chargement ou l'exportation peuvent être effectués à l'aide d'outils tels que Teradata Parallel Transporter, Fastload, Multiload, Fastexport et d'autres utilitaires fournis par Teradata.
Le mode incrémental d'intégration des données propose différentes méthodes telles que "insérer et mettre à jour", renommer les tables, "supprimer et insérer" ou des opérations de "merge".
Les "Query band" peuvent être utilisés pour tracer les commandes SQL générées par Stambia, ce qui constitue un moyen d'optimiser et de maîtriser les processus.
Especificaciones y prerrequisitos técnicos
| Especificación | Descripción |
|---|---|
|
Arquitectura simple y ágil |
|
|
Protocolos |
JDBC, HTTP, HTTPS |
|
Almacenamiento |
En función de la arquitectura, los siguientes almacenamientos pueden ser utilizados:
|
| Conectividad |
Puede extraer los datos de:
Para saber más, consulte nuestra documentación técnica |
| Conectividad técnica |
|
|
Datos estructurados y semiestructurados |
XML, JSON, Avro |
|
Características estándar |
|
| Características avanzadas |
|
| Prerrequisitos técnicos |
|
| Despliegue en la Nube | Image Docker disponible para los motores de ejecución (Runtime) y la consola de ejecución (Production Analytics) |
| Estándares soportados |
|
| Lenguaje de Scripting | Jython, Groovy, Rhino (Javascript), ... |
| Gestor de versionamiento | Cualquier plugin soportado por Eclipse : SVN, CVS, Git, ... |
| Migración desde su solución existente de integración de datos | Oracle Data Integrator (ODI) *, Informatica *, Datastage *, talend, Microsoft SSIS * posibilidad de migrar de manera simple y rápida |
¿Desea saber más?
Consulte nuestros diferentes recursos




¿No ha encontrado lo que deseaba en esta página?
Consulte otro de nuestros recursos
Stambia anuncia su fusión con Semarchy the Intelligent Data Hub™
Stambia Data Integration se convierte en Semarchy xDM Data Integration