
Stambia component for Big Query
Google Big Query is a serverless, highly scalable enterprise data warehouse, with no infrastructure to manage, that supports analytics over peta-byte scale data
Stambia component for Big Query provides a simple and agile way to integrate data to Big Query and then further use it to build solutions harnessing the elasticity in scaling from:
- the managed columnar storage
- massively parallel execution
- automatic performance optimization
Big Query Component : different Use Cases
Reduce your time to market
The intent of bringing your data on Google Big Query is to gain insights, out of huge volumes, faster.
Getting this data available to the Data Analyst and Data Scientist is important. Therefore, how quickly the Data Engineers can make this data available is key. Traditional solutions will always bring a lot of complexity in installation, configuration, design, maintenance etc.
A suitable Data Integration solution would be the one which, synergizes with Big Query, has a light footprint and is easy to use.

Migrate your On-Premise Data to Big Query
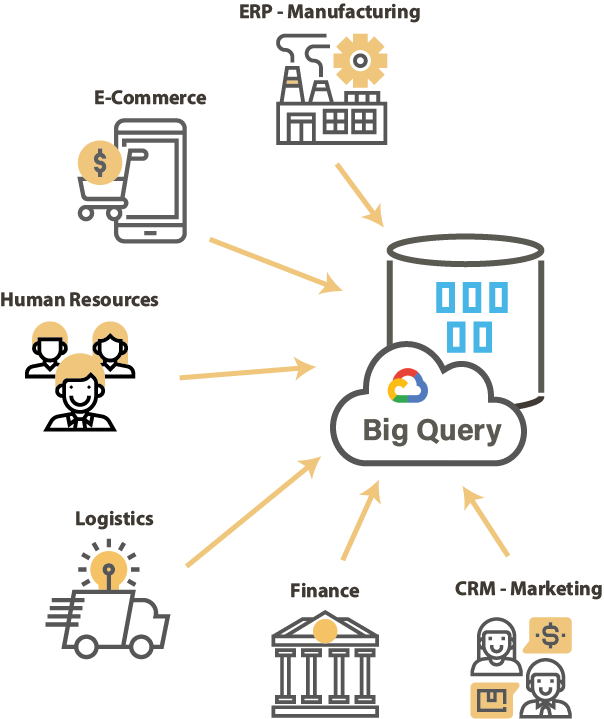
Migrating the on premise data is one of biggest challenge Involving a lot of unseen issues that possibly become hurdles in your Cloud adoption. In case of no architectural changes it could be relatively simple, but most of the cloud initiatives seek modernization of the Information System, hence the migration demands changes and enhancements to the data and it's architecture.
Data migration experts need tools and utilities that can migrate and enhance data quickly and provide the ability to be customized as a solution.
From their perspective, ready-to use migration utilities make it easier to get over with the simpler data and customizability of the solution helps in overcoming hidden issues as they come during the various phases of migration.
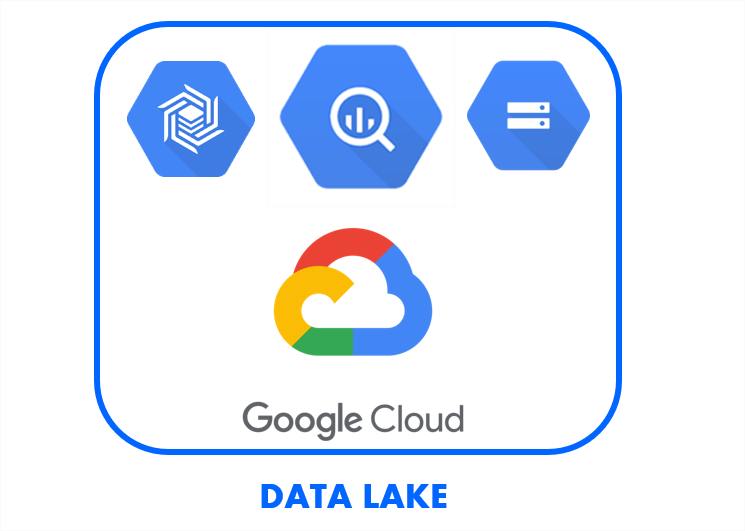
Build a Datalake
Google Cloud Platform is one of the most suitable platforms for building a Data Lake, with Big Query playing a key role. Raw data can be staged in Cloud Storage, which then can be used to load Big Query tables to define a data layer that is refined or can be provided to the analytics teams to build there ML models etc.
In a Data Lake project it is really important to deal with different kind of datasets, residing in different types of technologies, formats etc. Integrating to these different types of technology is the key requirement without overwhelming the architecture with too many integration solution.
Master the cost and reduce TCO

One of the major benefits of using Big Query is to have a control over cost of ownership. The architecture and the solutions involved in a Google cloud project must go hand in hand with this philosophy.
Data Integration solutions often come with a direct(clear) and indirect(hidden) cost that makes it difficult to understand the overall cost incurred.
The integration solution should have clear cost of ownership and must provide a readable trajectory so as to help define clear objectives
Features of Stambia Component for Big Query
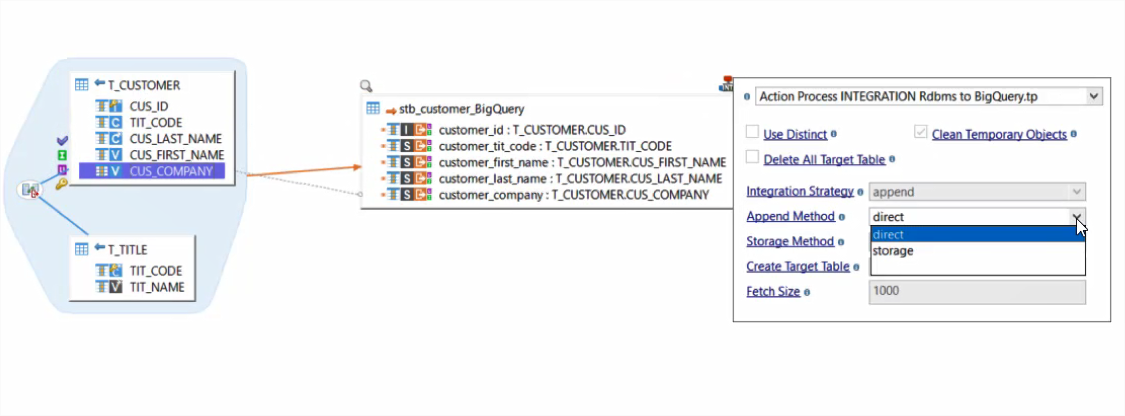
Stambia Component for Big Query allows users to quickly connect to the Datasets and perform drag n drop based data mappings. Users can set-up various load methods which could be:
- Direct Load
- Via Cloud Storage
- Stream
The various integration approaches available in Stambia's Big Query templates, simplifies the design and save manual design time.
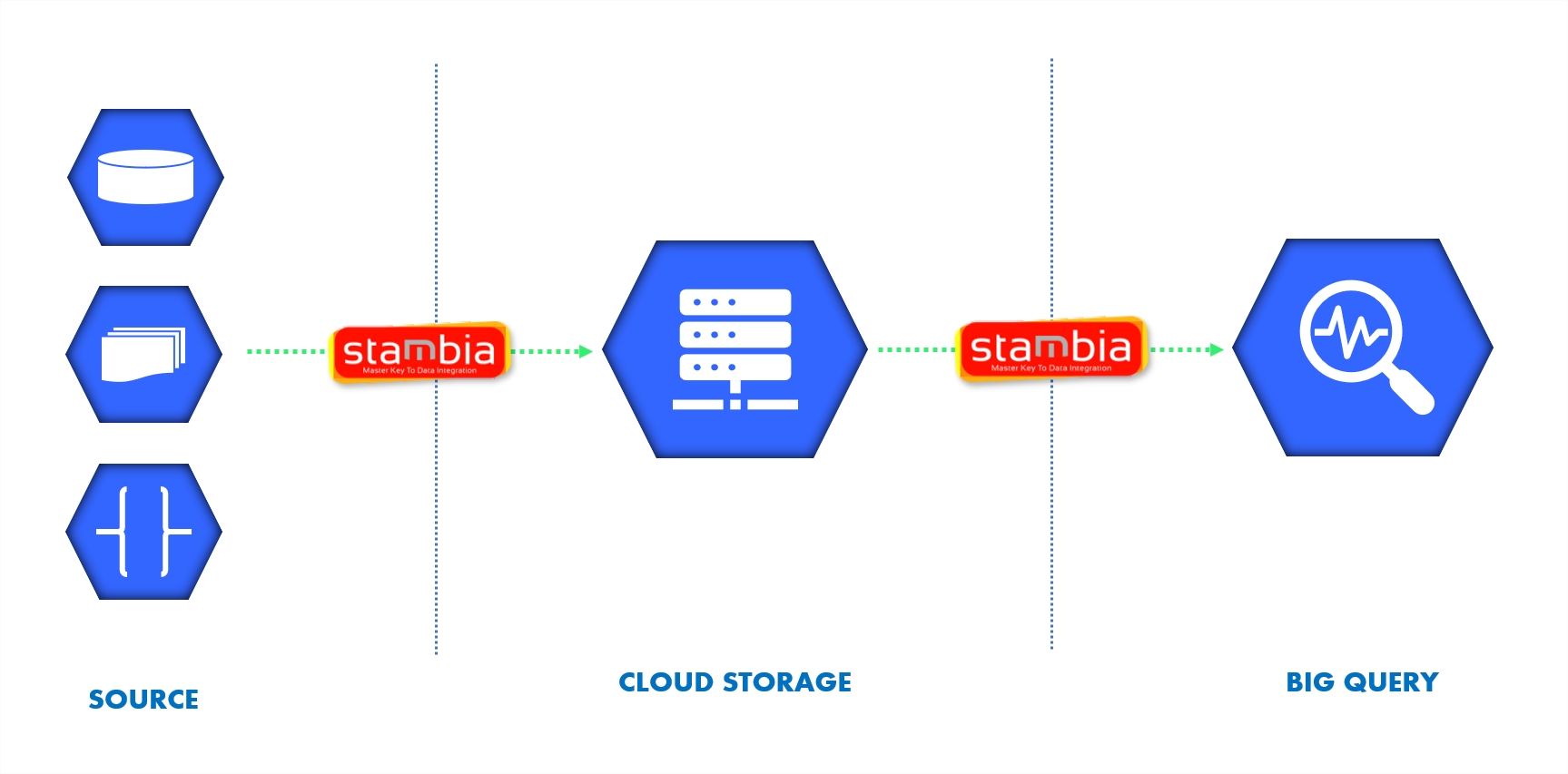
Expedite the Data Ingestion in Big Query with Stambia
Big Query component for Stambia is designed to simplify the Integration with an easy to use GUI and models designed to reduce manual coding and scripting. Stambia offers specifically designed Big Query Templates that have most of the codes already written so as to let users just simply perform drag and drop to setup their integration pipelines.
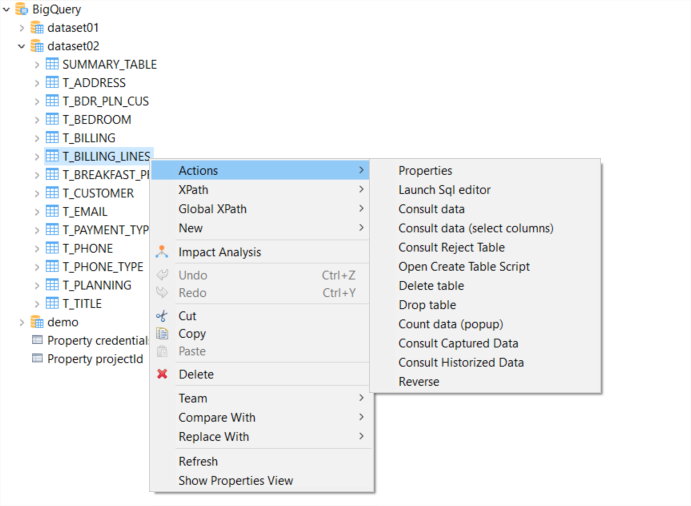
As well Big Query connectors is specifically designed from the standpoint of SQL developers so as to let them perform Standard SQL inside the Designer to work with Big Query in a much simpler way.
Simplify the Data Migration from your On-premise Legacy systems to Big Query
In Data Migration projects, Stambia helps in simplyfying the technological aspects of the project by creating customized solution that helps clear the unknown issues that frequently arise, so as to provide a much required flexibility from a Migration standpoint.
Stambia offers a replicator template specific to Big Query to let you move your data in just 4 steps. This template can be completely customized based on specific migration requirement.
Additionally, new templates can be quickly designed and delivered for any specific migration scenario, very quickly. This provides the project team a greater confidence in taking better decisions without any road block.
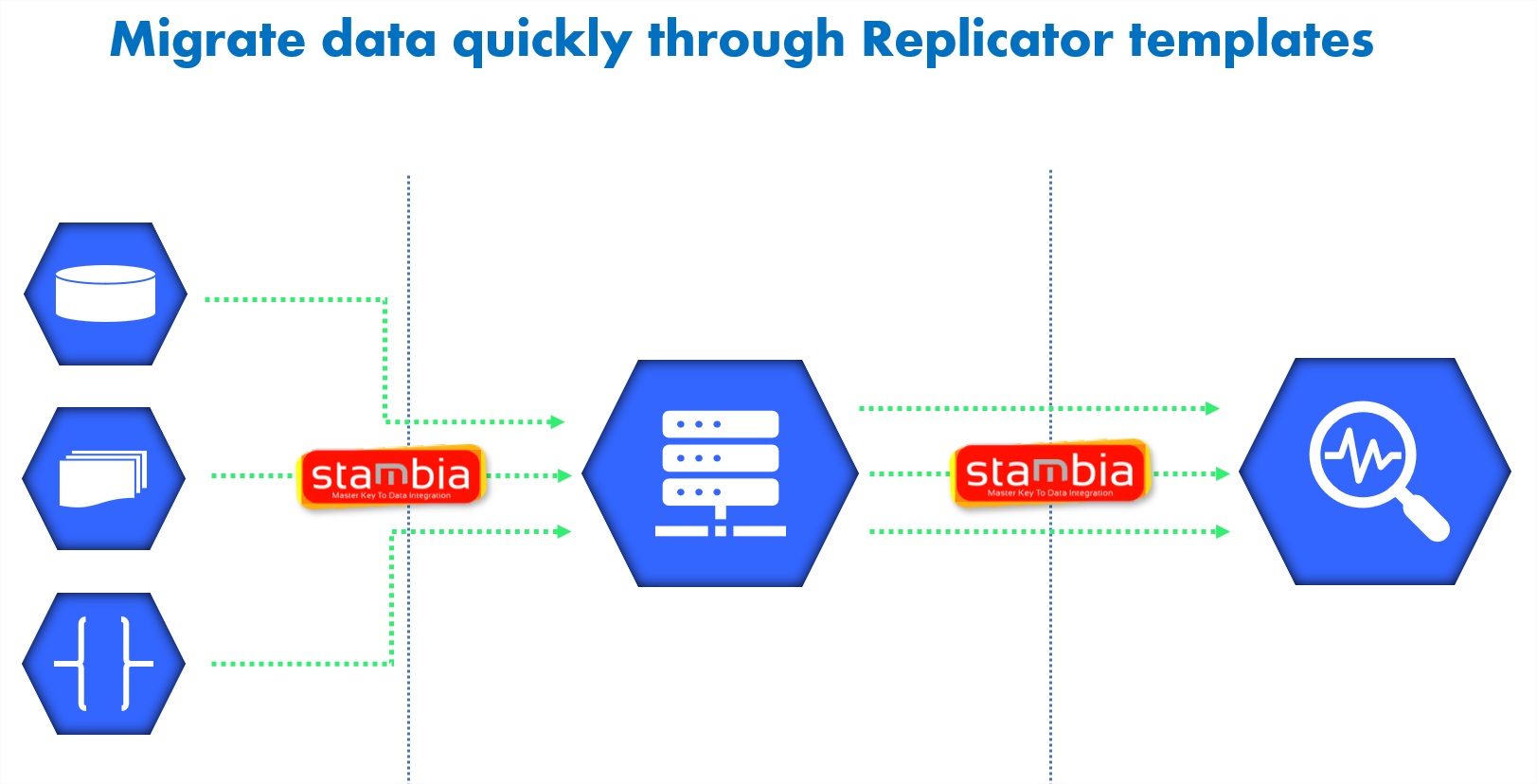
In order to know more about Data migration, take a look at a video about our "Replicator tool":
Use an Architecture Agnostic Integration Solution
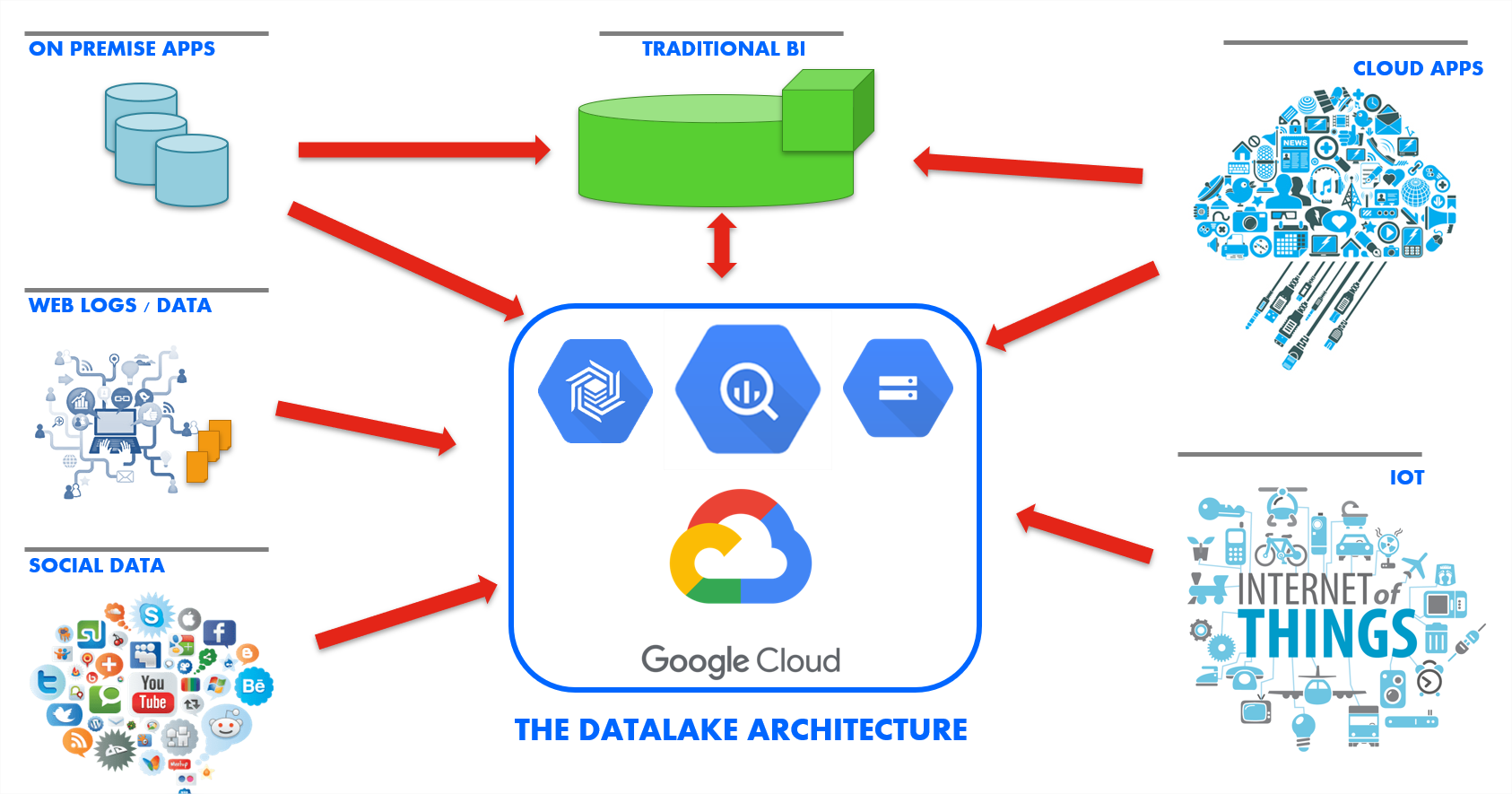
Stambia is a unified data integration solution, that can work with different kinds of architecture, platforms, technologies Etc. With the same solution you can start with a simple project on Big Query data ingestion and evolve to setting up a Data Lake in Google Cloud Platform.
Stambia offers connectivity to all sorts of databases from different technologies and Can seamlessly work with structured, semi-structured and unstructured data. This empowers the IT team to evolve their Information System's architecture with complete freedom.
Perform Analytics using the a Drag and Drop GUI
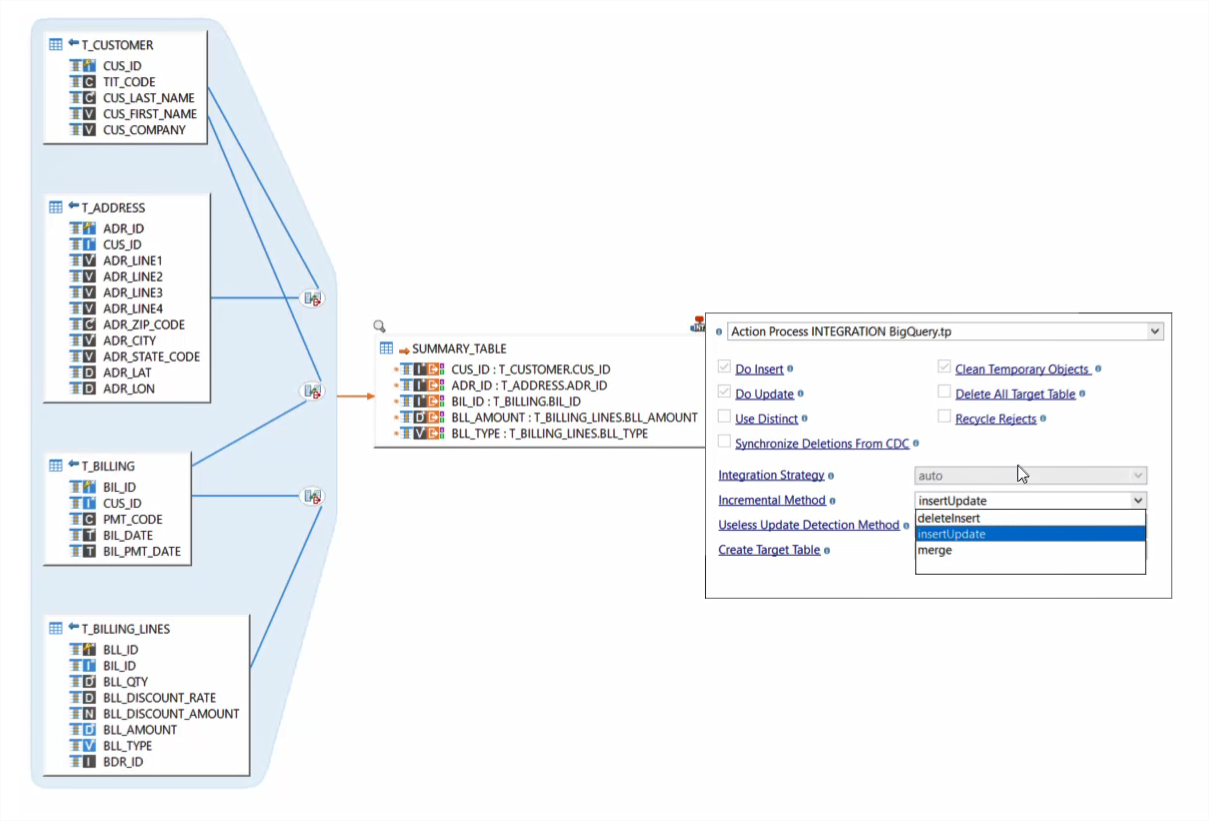
Big Query is known for delivering high-speed data analysis of large datasets. With Stambia, the users after ingesting Data to BQ, through drag n drop GUI based mappings, can perform some quick queries through the same GUI. The benefit of this is to have a visual sense of what is being done in a query without writing it manually and then on execution getting every detail of the query and it's output.
For e.g. in case of pulling data from a legacy system, the tables have referential integrity. When staged in BQ, another Set of mapping can be quickly created to join these staged data and create a denormalized view and store it in another BQ table
Greater confidence on Cost of Ownership
Stambia provides a simple and easy to read pricing model. With no focus on number of sources, data volumes to be handled, number of integration pipelines etc.
With a simple pricing Stambia Team works very closely in your projects to help you understand and define the phases of your project and have control over the cost at each step.

Technical specifications and prerequisites
| Specifications | Description |
|---|---|
|
Protocol |
JDBC, HTTP |
|
Structured and semi-structured |
XML, JSON, Avro (coming soon) |
|
Storage |
When integrating data into Google BigQuery using Cloud Storage, you have the choice of how it should be done:
|
| Connectivity |
You can extract data from :
For more information, consult the technical documentation |
|
Standard features |
|
| Advanced features | Stambia's Google BigQuery connector is using Standard SQL as default query mode. All statements supported by Google BigQuery's Standard SQL can therefore be used seamlessly without any particular configuration. Data can be sent to Google BigQuery with the following methods:
|
| Stambia Version | From Stambia Designer s18.3.8 |
| Stambia Runtime version | From Stambia Runtime s17.4.7 |
| Notes |
|
Want to know more ?
Consult our resources



Did not find what you want on this page?
Check out our other resources:

Discover in just 30 minutes : Sambia + Google BigQuery
Webinar : How to accelerate data integration to Google BigQuery?

Replay : Teradata Vantage with Hybrid Integration Platform
Semarchy has acquired Stambia
Stambia becomes Semarchy xDI Data Integration