
Stambia Component for Apache Kafka
Apache Kafka is a distributed data streaming platform that moves data from various sources (producers) to various targets (consumers).
Kafka is widely used to build real-time data streaming pipelines and applications.
Stambia Component for Apache Kafka, provides the ability to build your data pipelines, using a simple GUI to bring agility and productivity in your implementation..

Data Integration solution Key Factors?
Manage Kafka without writing code
Apache Kafka is widely adopted, as a data streaming platform, to cater to various data movements between various systems and applications.
Building these real-time data streaming pipelines and applications requires creating and managing complex codes, by the IT teams.
With an effective data integration solution, this effort of writing and managing manual code can be reduced significantly.
Thereby, bringing agility and flexibility in your projects, where users focus on what to do, rather than how to do.

Seamlessly work with Schema Registry

One of the important challenges, in handling evolving data schemas in Kafka, is addressed by Schema Registry.
This sits outside of Apache Kafka and helps in providing flexibility to interact and reduces the operational complexity.
With this, comes the task to also manage these schema registries.
When adopting an integration solution for Kafka, the ability to work seamlessly with Schema Registry to automate efforts, should be one of the key considerations.
Ability to work consistently with different formats
When working with Kafka, there are many data formats in which data gets moved from the source to sink. With the Schema Registry, developers need to work with AVRO, JSON and so on.
An Integration solution, when used, should automate and simplify managing various formats to reduce any human error, due to manual efforts..

Benefit from a Unified solution to connect to various technologies
In any data project, in your Information System, there will be various other use cases to cater to.
Managing data exchanges using Kafka, could possibly be one of those use cases.
With different kinds of technologies, platforms, databases, file formats, having a Data Integration solution that is Unified, sits at the center of the entire technological landscape, and caters to all sorts of data requirements, makes a lot of things easier for the data engineers.
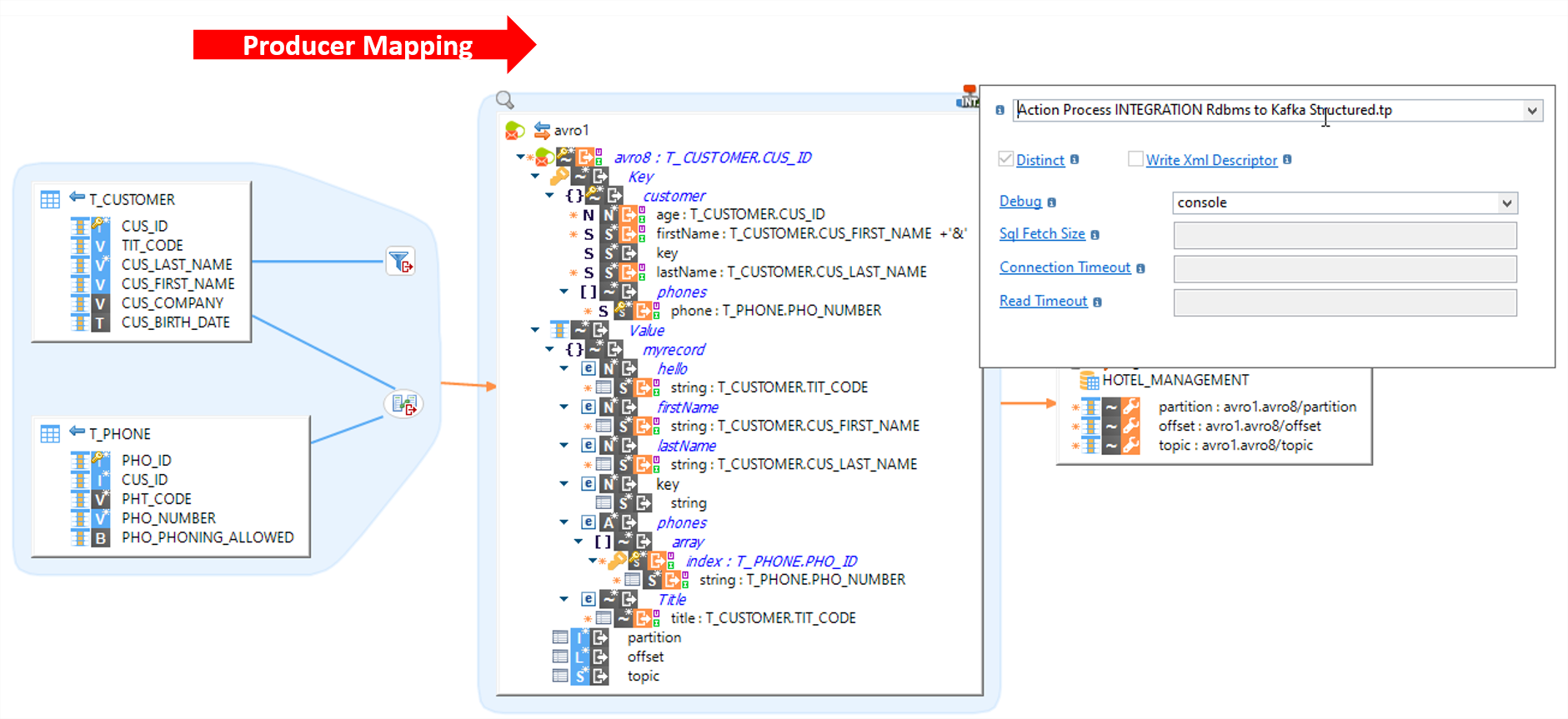
Stambia component for Apache Kafka allows users to easily manage data movements between sources and targets with simple drag and drop.
The solution is completely templatized to provide agility and flexibility in your projects.
Some of the key feature of this component is the ability to seamlessly manage:
Schema Registry
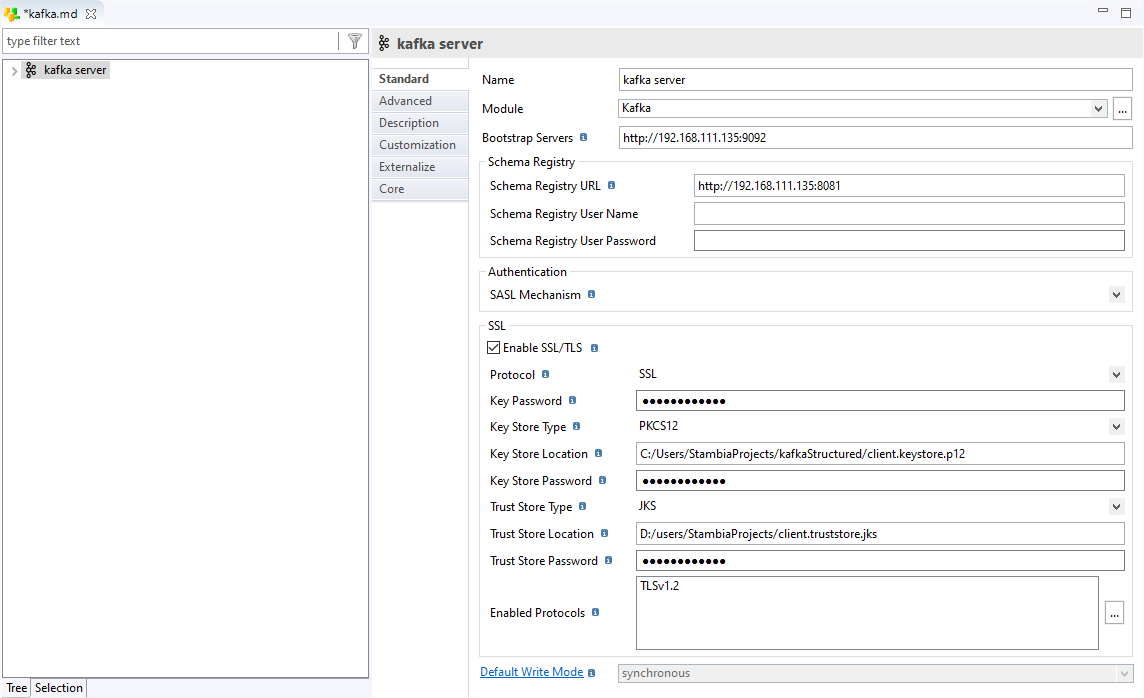
Metadata for Kafka in Stambia can be configured to connect to Confluent Schema Registry with SSL encryption to secure Kafka cluster.
This Schema then are created as a JSON / Avro Metadata separately.
Stambia Templates for Kafka uses this information to automatically manage the Schema creation and updates during executions.
Topics
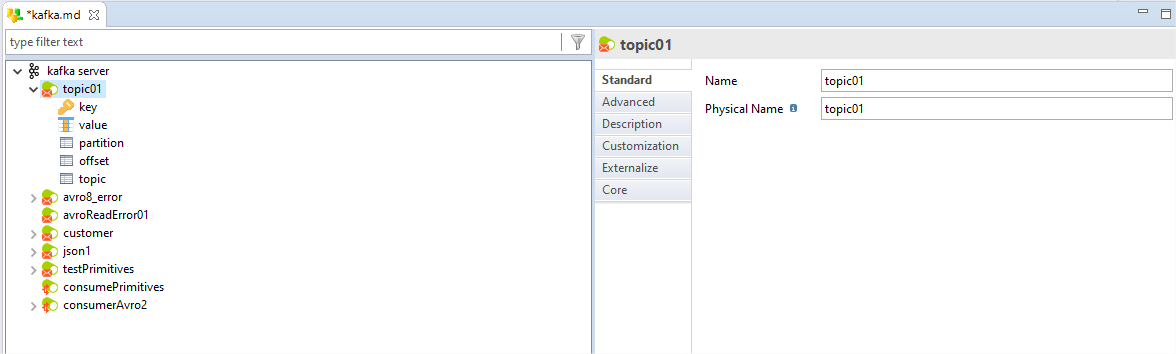
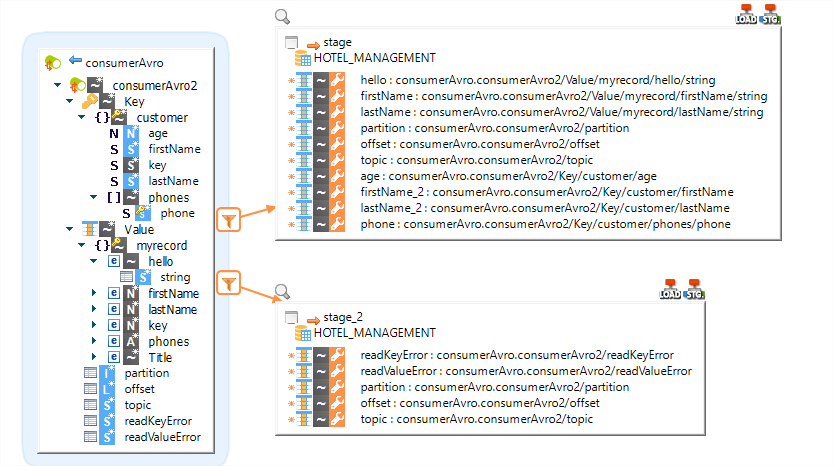
Topics can be configured in the metadata to have key, value created, where the schema as a JSON / Avro can be created, just with a drag n drop of the respective metadata of the formats.
This way the entire process of managing the evolving schema becomes metadata-driven and reduces complexity.
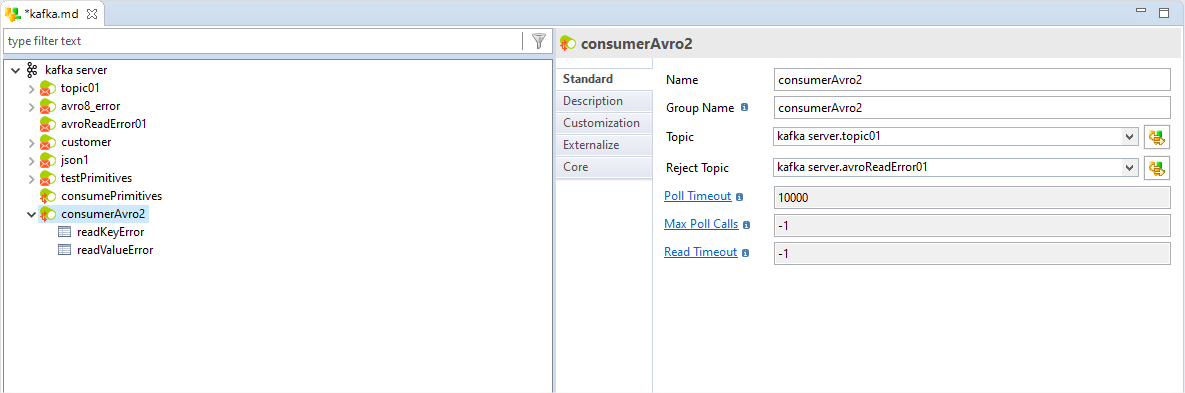
Consumers
Similarly, Consumers can be configured to point to a specific topic. This also allows to provide a reject topic where the rejected / erroneous records can be moved without causing a failure.
Simplicity and Agility with no need to write manual code
With the Kafka Component, users can quickly configure the metadata and get going with different mappings to Produce and Consume data wherever required.
The dedicated templates do the heavy lifting of generating the code, as well, managing the Schema Registry.
As a result, the focus is on what to do than how to..
Stambia, A Unified Solution for data projects
Stambia being a Unified solution can cater to various needs of connecting to different technologies and integrating to different architecture.
Apart from managing Kafka, users can work with various source and target databases, applications, big data technologies, data frameworks like Apache Spark and so on.
This results in creating a consistent integration layer and increases productivity of the team.
Technical specifications and prerequisites
| Specifications | Description |
|---|---|
|
Protocol |
JDBC, HTTP |
|
Structured and Sem-Structured |
AVRO, JSON |
|
Languages Supported |
JAVA |
| Connectivity |
You can extract data from : • Any relational database system such as Oracle, PostgreSQL, MSSQL, ...
|
|
Schema Registry |
Confluent Schema Registry |
|
Data loading performances |
Performances are improved when loading or extracting data through a bunch of options on the connectors allowing to customize how data is processed such as choosing a Spark jdbc load, or specifc data loaders from the database. |
| Stambia Runtime Version | Stambia DI Runtime S17.4.6 or higher |
Want to know more ?
Consult our resources



Did not find what you want on this page?
Check out our other resources:
Semarchy has acquired Stambia
Stambia becomes Semarchy xDI Data Integration