
No SQL data (XML, Json, Avro, Copybook Cobol…) with simplicity
Data file management is a topical issue, especially in the era of Big Data and NoSQL.
More and more data is stored in flat file or hierarchical file structures (Json, XML, etc.), some of which are very specific to the field of Big Data such as Avro. These hierarchical structures are either available directly in the file system (Windows, Linux, Hdfs, Amazon, Azure, etc.) or encapsulated in third-party technology (Elastic Search, Mongo DB, Big Query, Snowflake, Teradata, etc.).
Discover the features of Stambia which allow you to speed up projects requiring the use of files and hierarchical structures.

XML, JSON, Avro… Why is it sometimes complicated?
Traditional ETL solutions adapted to simple formats
Traditional data integration solutions have very often been designed for data in tabular format.
Hierarchical data management is achievable but costly in terms of development time and sometimes ineffective in terms of performance.
It is not uncommon to waste a lot of time and energy in projects handling simple hierarchical data (files from large systems, files with Copybook Cobol, NoSQL data like JSON or Avro, data from web services in XML, etc.).

Data volume issues

Things often get complicated when the volume of data increases.
Two scenarios can arise:
- Each file is large and requires a significant increase in machine power, especially memory, so that the file can be read without failure of the ELT.
- The number of files is large and the parallelization mechanisms are not efficient. As a result, the time required to process a batch of files can prove to be prohibitive or penalizing for operating teams.
XML, JSON ... Data formats that are not always easy to understand
Finally, not everyone is a specialist in hierarchical technologies, particularly Web Services or very specific formats like Avro or Json.
The manipulation of such structures with traditional or Open Source solutions can require significant technical skills and slow the reaction time compared to a business request.
Every little peculiarity (a type of data not included or a specific format of the file) can lead to waste a lot of time..

The manipulation of such structures with traditional or Open Source solutions can require significant technical skills and slow the reaction time compared to a business request.
Every little peculiarity (a type of data not included or a specific format of the file) can lead to waste a lot of time.
How does Stambia ETL manage hierarchical structures?
1. Simplifying the use of hierarchical data with Stambia ETL
Data representation by metadata
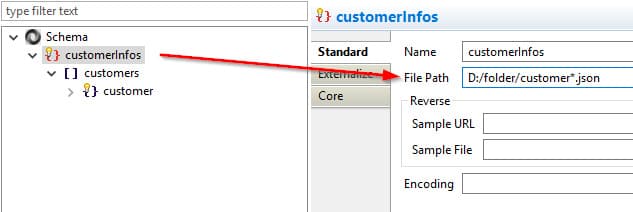
File management in Stambia is simple.
Many wizards help the user recover metadata. They are adapted to each technology, taking into account each specificity.
Where technology allows it, Stambia will offer to use specific reverse engineering standards (XSD, DTD, WSDL, etc.) When it is not the case (more free format), the assistant will propose to use example data in order to recover the maximum of information.
At any time, the user can correct and add his own information in order to have a description of the objects that is most faithful to the data he will have to process..
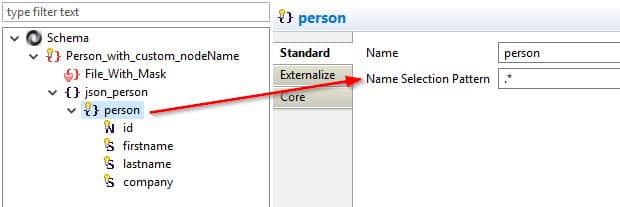
Exploring the hierarchical data
The Stambia Designer allows to read directly hierarchical data types JSON or Avro, with a specialized editor.
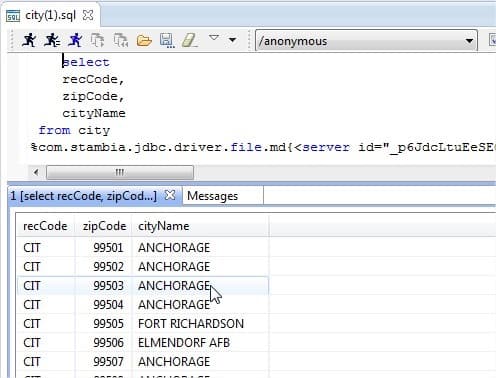
In the case of other hierarchical files, the unequal connector, which is a JDBC driver, can read or write files of delimited or fixed length and can handle events within the same line (variable length of the same line type).
Once the description of the file has been made, it is possible to perform simple SQL commands to read the file as if it were composed of several tables (see image opposite).)
2. Reading and writing hierarchical data efficiently
Reading / loading hierarchical data with Stambia
Stambia's universal mapping provides the best way to read complex files in order to load multiple targets, with a very high level of performance.
Indeed, the "multi-target" approach to mapping remains simple, while making it possible to load multiple targets from a single file. The files will be loaded at once, but the data will be sent at the same time (or according to the requested sequence) to several targets.
This provides a high level of performance for reading, using and transforming hierarchical source data.
This approach is also data-oriented. It allows the user to focus on the link between his data and not on the technical process which is necessary for the realization of the mapping.
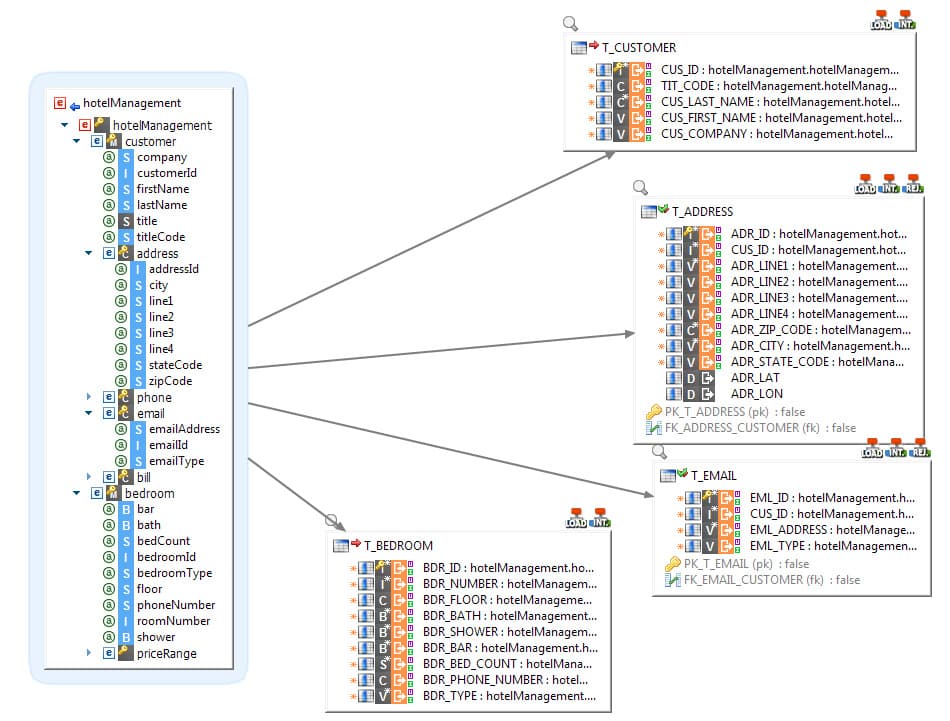
Writing hierarchical data with Stambia
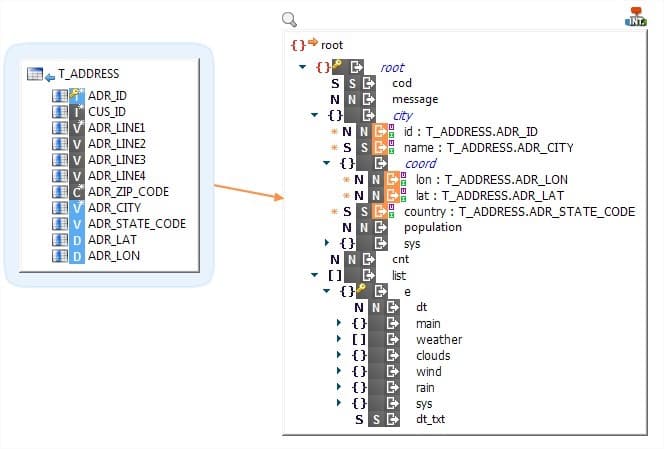
Stambia can integrate the data in a hierarchical file or structure in a single mapping, regardless of the complexity of the structure addressed.
In the example provided, the target of the mapping is an XML file composed of several hierarchies.
While remaining legible, a single mapping will produce a single hierarchical file, which may contain very deep hierarchies, or multiple occurrences of the same elements, or even juxtaposed hierarchies.
Like reading data, this approach is also data oriented (data-centric). It allows the user to focus on the link between his data and not on the technical process which is necessary for the realization of the mapping.
This approach is also very useful when using Web Services or APIs which use this type of hierarchical data for inputs or outputs.
3. Automating and industrializing with Stambia ETL
Industrializing the reading or writing of files in directories
Manipulating files sometimes requires iterating the same operations on several identical files.
For example, reading several identical files in source and iterating: several orders or batches of orders to integrate into an ERP or CRM. Or even generating several files from the same source dataset: generating e a file by city or by supplier.
These operations can be complex with traditional solutions.
Stambia offers many features that automate these processes, notably the possibility to manage in a mapping the directory or file level in order to automate (without the use of additional technical processes) the batch reading or writing of hierarchical structures.
This approach makes it possible to keep a business-oriented (data-centric) vision of developments, and above all, to guarantee optimal performance during batch processing of large files.
Automatically replicating hierarchical data (XML, JSON, Avro…)

Integration of source files into a target can also be automated using the replication component.
This component allows you to browse a directory and massively integrate files into a relational database or any other structured target.
In this case, there is no mapping or development. The replicator is able to create a relational structure (or other) from a hierarchical file structure and to complete the database with files that have been found in the folder.
This type of component can incorporate incremental integration mechanisms (with calculation of the differences) to integrate data in a target coherently and without duplicates.
Many wizards help the user recover metadata. They are adapted to each technology, taking into account each specificity.
Where technology allows it, Stambia will offer to use specific reverse engineering standards (XSD, DTD, WSDL, etc.) When it is not the case (more free format), the assistant will propose to use example data in order to recover the maximum of information.
At any time, the user can correct and add his own information in order to have a description of the objects that is most faithful to the data he will have to process.
Technical Specifications
| Specification | Description |
|---|---|
|
Simple and agile architecture |
|
|
Protocol |
HDFS, GCS, Azure Cloud HTTP REST / SOAP |
|
Data Format |
XML, JSON, AVRO, and any specific format ASCII, EBCDIC, Packed amounts, Parquet, ... |
| Connectivity |
You can extract or integrate data from:
For more information, consult our technical documentation |
| Technical Connectivity |
|
|
Standard Characteristics |
|
| Advanced characteristics |
|
| Technical prerequisites |
|
| Cloud Deployment | Image Docker disponible pour les moteurs d'exécution (Runtime) et la console d'exploitation (Production Analytics) |
| Supported Standards |
|
|
Scripting Language |
Jython, Groovy, Rhino (Javascript), ... |
| Source Manager | Any Eclipse-supported plugin : SVN, CVS, Git, ... |
Want to know more?
Consult our resources




Did not find what you want on this page?
Check out our other resources:

Management of hierarchical data formats such as XML, JSON, SAP IDOCS or Web Services can be very complex.
Which developer has never complained about the difficulty and the time losses induced by the processing of this type of data?
This is understandable since traditional data integration solutions, designed for simpler data formats such as tables and flat files, encounter poor productivity and performance when dealing with this type of structure. ...
Semarchy has acquired Stambia
Stambia becomes Semarchy xDI Data Integration